


This post was co-written with Le Vy from Parcel Perform.
Access to accurate data is often the true differentiator of excellent and timely decisions. This is even more crucial for customer-facing decisions and actions. A correctly implemented state-of-the-art AI can help your organization simplify access to data for accurate and timely decision-making for the customer-facing business team, while reducing the undifferentiated heavy lifting done by your data team. In this post, we share how Parcel Perform, a leading AI Delivery Experience Platform for e-commerce businesses worldwide, implemented such a solution.
Accurate post-purchase deliveries tracking can be crucial for many ecommerce merchants. Parcel Perform provides an AI-driven, intelligent end-to-end data and delivery experience and software as a service (SaaS) system for ecommerce merchants. The system uses AWS services and state-of-the-art AI to process hundreds of millions of daily parcel delivery movement data and provide a unified tracking capability across couriers for the merchants, with emphasis on accuracy and simplicity.
The business team in Parcel Perform often needs access to data to answer questions related to merchants’ parcel deliveries, such as “Did we see a spike in delivery delays last week? If so, in which transit facilities were this observed, and what was the primary cause of the issue?” Previously, the data team had to manually form the query and run it to fetch the data. With the new generative AI-powered text-to-SQL capability in Parcel Perform, the business team can self-serve their data needs by using an AI assistant interface. In this post, we discuss how Parcel Perform incorporated generative AI, data storage, and data access through AWS services to make timely decisions.
Data analytics architecture
The solution starts with data ingestion, storage, and access. Parcel Perform adopted the data analytics architecture shown in the following diagram.

One key data type in the Parcel Perform parcel monitoring application is the parcel event data, which can reach billions of rows. This includes the parcel’s shipment status change, location change, and much more. This day-to-day data from multiple business units lands in relational databases hosted on Amazon Relational Database Service (Amazon RDS).
Although relational databases are suitable for rapid data ingestion and consumption from the application, a separate analytics stack is needed to handle analytics in a scalable and performant way without disrupting the main application. These analytics needs include answering aggregation queries from questions like “How many parcels were delayed last week?”
Parcel Perform uses Amazon Simple Storage Service (Amazon S3) with a query engine provided by Amazon Athena to meet their analytics needs. With this approach, Parcel Perform benefits from cost-effective storage while still being able to run SQL queries as needed on the data through Athena, which is priced on usage.
Data in Amazon S3 is stored in Apache Iceberg data format that allows data updates, which is useful in this case because the parcel events sometimes get updated. It also supports partitioning for better performance. Amazon S3 Tables, launched in late 2024, is a managed Iceberg tables feature that can also be an option for you.
Parcel Perform uses an Apache Kafka cluster managed by Amazon Managed Streaming for Apache Kafka (Amazon MSK) as the stream to move the data from the source to the S3 bucket. Amazon MSK Connect with a Debezium connector streams data with change data capture (CDC) from Amazon RDS to Amazon MSK.
Apache Flink, running on Amazon Elastic Kubernetes Service (Amazon EKS), processes data streams from Amazon MSK. It writes this data to an S3 bucket according to the Iceberg format, and updates the data schema in the AWS Glue Data Catalog. The data schema enables Athena to correctly query the data in the S3 bucket.
Now that you understand how the data is ingested and stored, let’s show how the data is consumed using the generative AI-powered data serving assistant for the business teams in Parcel Perform.
AI agent that can query data
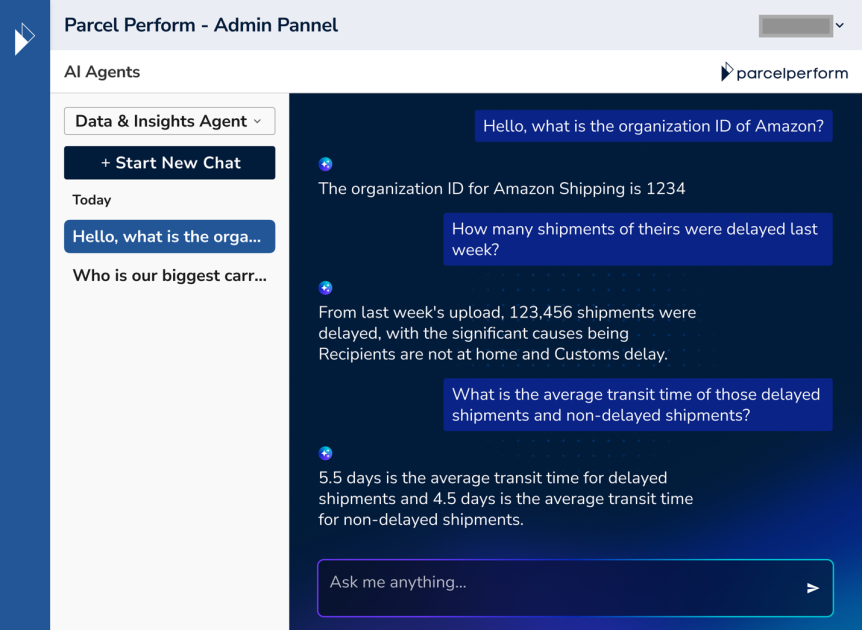
The users of the data serving AI agent in Parcel Perform are customer-facing business team members who often query the parcel event data to answer questions from ecommerce merchants regarding the parcel deliveries and to proactively assist them. The following screenshot shows the UI experience for the AI agent assistant, powered by text-to-SQL with generative AI.

This functionality helped the Parcel Perform team and their customers save time, which we discuss later in this post. In the following section, we present the architecture that powers this feature.
Text-to-SQL AI agent architecture
The data serving AI assistant architecture in Parcel Perform is shown in the following diagram.
 The AI assistant UI is powered by an application built with the Fast API framework hosted on Amazon EKS. It is also fronted by an Application Load Balancer to allow for potential horizontal scalability.
The AI assistant UI is powered by an application built with the Fast API framework hosted on Amazon EKS. It is also fronted by an Application Load Balancer to allow for potential horizontal scalability.
The application uses LangGraph to orchestrate the workflow of large language model (LLM) invocations, the use of tools, and the memory checkpointing. The graph uses multiple tools, including those from SQLDatabase Toolkit, to automatically fetch the data schema through Athena. The graph also uses an Amazon Bedrock Knowledge Bases retriever to retrieve business information from a knowledge base. Parcel Perform uses Anthropic’s Claude models in Amazon Bedrock to generate SQL.
Although the function of Athena as a query engine to query the parcel event data on Amazon S3 is clear, Parcel Perform still needs a knowledge base. In this use case, the SQL generation performs better when the LLM has more business contextual information to help interpret database fields and translate logistics terminology into data representations. This is better illustrated with the following two examples:
- Parcel Perform’s data lake operations use specific codes:
cfor create andufor update. When analyzing data, Parcel Perform sometimes needs to focus only on initial creation records, where operation code is equal toc. Because this business logic might not be inherent in the training of LLMs in general, Parcel Perform explicitly defines this in their business context. - In logistics terminology, transit time has specific industry conventions. It’s measured in days, and same-day deliveries are recorded as
transit_time = 0. Although this is intuitive for logistics professionals, an LLM might incorrectly interpret a request like “Get me all shipments with same-day delivery” by usingWHERE transit_time = 1instead ofWHERE transit_time = 0in the generated SQL statement.
Therefore, each incoming question goes to a Retrieval Augmented Generation (RAG) workflow to find potentially relevant stored business information, to enrich the context. This mechanism helps provide the specific rules and interpretations that even advanced LLMs might not be able to derive from general training data.
Parcel Perform uses Amazon Bedrock Knowledge Bases as a managed solution for the RAG workflow. They ingest business contextual information by uploading files to Amazon S3. Amazon Bedrock Knowledge Bases processes the files, converts them to chunks, uses embedding models to generate vectors, and stores the vectors in a vector database to make them searchable. The steps are fully managed by Amazon Bedrock Knowledge Bases. Parcel Perform stores the vectors in Amazon OpenSearch Serverless as the vector database of choice to simplify infrastructure management.
Amazon Bedrock Knowledge Bases provides the Retrieve API, which takes in an input (such as a question from the AI assistant), converts it into a vector embedding, searches for relevant chunks of business context information in the vector database, and returns the top relevant document chunks. It is integrated with the LangChain Amazon Bedrock Knowledge Bases retriever by calling the invoke method.
The next step involves invoking an AI agent with the supplied business contextual information and the SQL generation prompt. The prompt was inspired by a prompt in LangChain Hub. The following is a code snippet of the prompt:
The prompt sample is part of the initial instruction for the agent. The data schema is automatically inserted by the tools from the SQLDatabase Toolkit at a later step of this agentic workflow. The following steps occur after a user enters a question in the AI assistant UI:
- The question triggers a run of the LangGraph graph.
- The following processes happen in parallel:
- The graph fetches the database schema from Athena through SQLDatabase Toolkit.
- The graph passes the question to the Amazon Bedrock Knowledge Bases retriever and gets a list of relevant business information regarding the question.
- The graph invokes an LLM using Amazon Bedrock by passing the question, the conversation context, data schema, and business context information. The result is the generated SQL.
- The graph uses SQLDatabase Toolkit again to run the SQL through Athena and fetch the data output.
- The data output is passed into an LLM to generate the final response based on the initial question asked. Amazon Bedrock Guardrails is used as a safeguard to avoid inappropriate inputs and responses.
- The final response is returned to the user through the AI assistant UI.
The following diagram illustrates these steps.

This implementation demonstrates how Parcel Perform transforms raw inquiries into actionable data for timely decision-making. Security is also implemented in multiple components. From a network perspective, the EKS pods are placed in private subnets in Amazon Virtual Private Cloud (Amazon VPC) to improve network security of the AI assistant application. This AI agent is placed behind a backend layer that requires authentication. For data security, sensitive data is masked at rest in the S3 bucket. Parcel Perform also limits the permissions of the AWS Identity and Access Management (IAM) role used to access the S3 bucket so it can only access certain tables.
In the following sections, we discuss Parcel Perform’s approach to building this data transformation solution.
From idea to production
Parcel Perform started with the idea of freeing their data team from manually serving the request from the business team, while also improving the timeliness of the data availability to support the business team’s decision-making.
With the help of the AWS Solutions Architect team, Parcel Perform completed a proof of concept using AWS services and a Jupyter notebook in Amazon SageMaker Studio. After an initial success, Parcel Perform integrated the solution with their orchestration tool of choice, LangGraph.
Before going into production, Parcel Perform conducted extensive testing to verify the results were consistent. They added LangSmith Tracing to log the AI agent’s steps and results to evaluate its performance.
The Parcel Perform team discovered challenges during their journey, which we discuss in the following section. They performed prompt engineering to address those challenges. Eventually, the AI agent was integrated into production to be used by the business team. Afterward, Parcel Perform collected user feedback internally and monitored logs from LangSmith Tracing to verify performance was maintained.
The challenges
This journey isn’t free from challenges. Firstly, some ecommerce merchants might have several records in the data lake under various names. For example, a merchant with the name “ABC” might have multiple records such, as “ABC Singapore Holdings Pte. Ltd.,” “ABC Demo Account,” “ABC Test Group,” and so on. For a question like “Was there any parcel shipment delay by ABC last week?”, the generated SQL has the element of WHERE merchant_name LIKE '%ABC%', which might result in ambiguity. During the proof of concept stage, this problem caused incorrect matching of the result.
For this challenge, Parcel Perform relies on careful prompt engineering to instruct the LLM to identify when the name was potentially ambiguous. The AI agent then calls Athena again to look for matching names. The LLM decides which merchant name to use based on multiple factors, including the significance in data volume contribution and the account status in the data lake. In the future, Parcel Perform intends to implement a more sophisticated technique by prompting the user to resolve the ambiguity.
The second challenge is about unrestricted questions that might yield expensive queries running across large amounts of data and resulting in longer query waiting time. Some of these questions might not have a LIMIT clause imposed in the query. To solve this, Parcel Perform instructs the LLM to add a LIMIT clause with a certain number of maximum results if the user doesn’t specify the intended number of results. In the future, Parcel Perform plans to use the query EXPLAIN results to identify heavy queries.
The third challenge is related to tracking usage and incurred cost of this particular solution. Having started multiple generative AI projects using Amazon Bedrock and sometimes with the same LLM ID, Parcel Perform must distinguish usage incurred by projects. Parcel Perform creates an inference profile for each project, associates the profile with tags, and includes that profile in each LLM call for that project. With this setup, Parcel Perform is able to segregate costs based on projects to improve cost visibility and monitoring.
The impact
To extract data, the business team clarifies details with the data team, makes a request, checks feasibility, and waits for bandwidth. This process lengthens when requirements come from customers or teams in different time zones, with each clarification adding 12–24 hours due to asynchronous communication. Simpler requests made early in the workday might complete within 24 hours, whereas more complex requests or those during busy periods can take 3–5 business days.
With the text-to-SQL AI agent, this process is dramatically streamlined—minimizing the back-and-forth communication for requirement clarification, removing the dependency on data team bandwidth, and automating result interpretation.
Parcel Perform’s measurements show that the text-to-SQL AI agent reduces the average time-to-insight by 99%, from 2.3 days to an average of 10 minutes, saving approximately 3,850 total hours of wait time per month across requesters while maintaining data accuracy.
Users can directly query the data without intermediaries, receiving results in minutes rather than days. Teams across time zones can now access insights any time of day, alleviating the frustrating “wait until Asia wakes up” or “catch EMEA before they leave” delays, leading to happier customers and faster problem-solving.
This transformation has profoundly impacted the data analytics team’s capacity and focus, freeing the data team for more strategic work and helping everyone make faster, more informed decisions. Before, the analysts spent approximately 25% of their working hours handling routine data extraction requests—equivalent to over 260 hours monthly across the team. Now, with basic and intermediate queries automated, this number has dropped to just 10%, freeing up nearly 160 hours each month for high-impact work. Analysts now focus on complex data analysis rather than spending time on basic data retrieval tasks.
Conclusion
Parcel Perform’s solution demonstrates how you can use generative AI to enhance productivity and customer experience. Parcel Perform has built a text-to-SQL AI agent that transforms a business team’s question into SQL that can fetch the actual data. This improves the timeliness of data availability for decision-making that involves customers. Furthermore, the data team can avoid the undifferentiated heavy lifting to focus on complex data analysis tasks.
This solution uses multiple AWS services like Amazon Bedrock and tools like LangGraph. You can start with a proof of concept and consult your AWS Solutions Architect or engage with AWS Partners. If you have questions, post them on AWS re:Post. You can also make the development more straightforward with the help of Amazon Q Developer. When you face challenges, you can iterate to find the solution, which might include prompt engineering or adding additional steps to your workflow.
Security is a top priority. Make sure your AI assistant has proper guardrails in place to protect against prompt threats, inappropriate topics, profanity, leaked data, and other security issues. You can integrate Amazon Bedrock Guardrails with your generative AI application through an API.To learn more, refer to the following resources:
About the authors
 Yudho Ahmad Diponegoro is a Senior Solutions Architect at AWS. Having been part of Amazon for 10+ years, he has had various roles from software development to solutions architecture. He helps startups in Singapore when it comes to architecting in the cloud. While he keeps his breadth of knowledge across technologies and industries, he focuses in AI and machine learning where he has been guiding various startups in ASEAN to adopt machine learning and generative AI at AWS.
Yudho Ahmad Diponegoro is a Senior Solutions Architect at AWS. Having been part of Amazon for 10+ years, he has had various roles from software development to solutions architecture. He helps startups in Singapore when it comes to architecting in the cloud. While he keeps his breadth of knowledge across technologies and industries, he focuses in AI and machine learning where he has been guiding various startups in ASEAN to adopt machine learning and generative AI at AWS.
 Le Vy is the AI Team Lead at Parcel Perform, where she drives the development of AI applications and explores emerging AI research. She started her career in data analysis and deepened her focus on AI through a Master’s in Artificial Intelligence. Passionate about applying data and AI to solve real business problems, she also dedicates time to mentoring aspiring technologists and building a supportive community for youth in tech. Through her work, Vy actively challenges gender norms in the industry and champions lifelong learning as a key to innovation.
Le Vy is the AI Team Lead at Parcel Perform, where she drives the development of AI applications and explores emerging AI research. She started her career in data analysis and deepened her focus on AI through a Master’s in Artificial Intelligence. Passionate about applying data and AI to solve real business problems, she also dedicates time to mentoring aspiring technologists and building a supportive community for youth in tech. Through her work, Vy actively challenges gender norms in the industry and champions lifelong learning as a key to innovation.
 Loke Jun Kai is a GenAI/ML Specialist Solutions Architect in AWS, covering strategic customers across the ASEAN region. He works with customers ranging from Start-up to Enterprise to build cutting-edge use cases and scalable GenAI Platforms. His passion in the AI space, constant research and reading, have led to many innovative solutions built with concrete business outcomes. Outside of work, he enjoys a good game of tennis and chess.
Loke Jun Kai is a GenAI/ML Specialist Solutions Architect in AWS, covering strategic customers across the ASEAN region. He works with customers ranging from Start-up to Enterprise to build cutting-edge use cases and scalable GenAI Platforms. His passion in the AI space, constant research and reading, have led to many innovative solutions built with concrete business outcomes. Outside of work, he enjoys a good game of tennis and chess.



