


Many enterprises are using large language models (LLMs) in Amazon Bedrock to gain insights from their internal data sources. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Organizations implementing conversational AI systems often face a common challenge: although their APIs can quickly find answers to targeted questions, more complex queries requiring reasoning-actioning (ReAct) logic can take substantial time to process, negatively impacting user experience. This issue is particularly pronounced in regulated industries where security requirements add additional complexity. For instance, a global financial services organization with over $1.5 trillion in assets under management encountered this exact challenge. Despite successfully implementing a conversational AI system that integrated with multiple LLMs and data sources, they needed a solution that could maintain their rigorous security protocols—including AWS services operating within virtual private cloud (VPC) environments and enterprise OAuth integration—while improving response times for complex queries.
AWS AppSync is a fully managed service that enables developers to build serverless GraphQL APIs with real-time capabilities. This post demonstrates how to combine AWS AppSync subscriptions with Amazon Bedrock streaming endpoints to deliver LLM responses incrementally. We provide an enterprise-grade implementation blueprint that helps organizations in regulated industries maintain security compliance while optimizing user experience through immediate real-time response delivery.
Solution overview
The solution discussed in this post uses AWS AppSync to start the asynchronous conversational workflow. An AWS Lambda function does the heavy lifting of interacting with the Amazon Bedrock streaming API. As the LLM produces tokens, they are streamed to the frontend using AWS AppSync mutations and subscriptions.
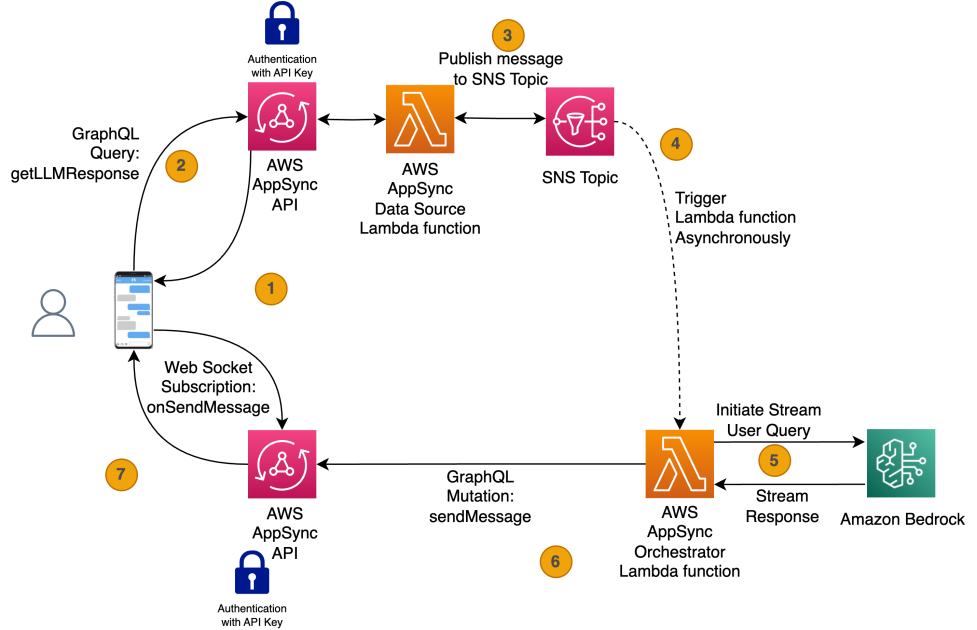
A reference implementation of the Lambda function and AWS AppSync API is provided in the sample code in this post. The following diagram illustrates the reference architecture. It provides a high-level overview of how the various AWS services are integrated to achieve the desired outcome.

Let’s traverse how a user’s request is handled in the solution, and how the user receives real-time responses from an LLM in Amazon Bedrock:
- When the user loads the UI application, the application subscribes to the GraphQL subscription
onSendMesssage(), which returns whether the WebSocket connection was successful or not. - After the user enters a query, it invokes a GraphQL query (
getLLMResponse) and triggers the Data Source Lambda function. - The Data Source Lambda function publishes an event to the Amazon Simple Notification Service (Amazon SNS) topic, and a 201 message is sent to the user, completing the synchronous flow.
These steps are better illustrated in the following sequence diagram.

- The Orchestrator Lambda function gets triggered by a published SNS event and initiates the stream with the Amazon Bedrock API call
InvokeModelWithResponseStream. - Amazon Bedrock receives the user query, initiates the stream, and starts sending stream tokens back to the Lambda function.
- When the Orchestrator Lambda function receives a stream token from Amazon Bedrock, the function invokes the GraphQL mutation
sendMessage. - The mutation triggers the
onSendMessagesubscription containing the LLM partial response, and the UI prints those stream tokens as it receives it.
The following diagram illustrates these steps in more detail.

In the following sections, we discuss the components that make up the solution in more detail.
Data and API design
The AppSync API GraphQL schema consists of query, subscription, and mutation operations.
The following code is the query operation:
The query operation, getLLMResponse, is synchronous and accepts sessionId, locale, and user-provided message.
The frontend must send a unique sessionId; this session ID uniquely identifies the user’s chat session. The session ID doesn’t change for the duration of active conversation. For example, if the user reloads the frontend, a new sessionId is generated and sent to the query operation.
The frontend must also send locale, which indicates the user’s preferred language. For a list of supported locales, see Languages and locales supported by Amazon Lex V2. For example, we use en_US for North American English.
Finally, the user’s message (or query) is set in the message attribute. The value of the message attribute is passed to the LLM for analysis.
The following code is the subscription operation:
The AWS AppSync subscription operation, onSendMessage, accepts sessionId as a parameter. The frontend calls the onSendMessage subscription operation to subscribe to a WebSocket connection using sessionId. This allows the frontend to receive messages from the AWS AppSync API whenever a mutation operation successfully executes for the given sessionId.
The following code is the mutation operation:
The mutation operation, sendMessage, accepts a payload of type SendMessageInput. The caller must provide all required attributes in the SendMessageInput type, indicated by the exclamation point in the GraphQL schema excerpt, to successfully send a message to the frontend using the mutation operation.
The Orchestrator Lambda function calls the sendMessage mutation to send partially received LLM tokens to the frontend. We discuss the Orchestrator Lambda function in more detail later in this post.
AWS AppSync Data Source Lambda function
AWS AppSync invokes the AWS AppSync Data Source Lambda function when the frontend calls the GraphQL query operation, getLLMResponse. The GraphQL query is a synchronous operation.
The implementation of the AWS AppSync Data Source Lambda function is in the following GitHub repo, called bedrock-appsync-ds-lambda. This Lambda function extracts the user’s message from the incoming GraphQL query operation and sends the value to the SNS topic. The Lambda function then returns success status code to the caller indicating that the message is submitted to the backend for processing.
AWS AppSync Orchestrator Lambda function
The AWS AppSync Orchestrator Lambda function runs whenever an event is published to the SNS topic. This function initiates the Amazon Bedrock streaming API using the converse_stream Boto3 API call.
The following code snippet shows how the Orchestrator Lambda function receives the SNS event, processes it, and then calls the Boto3 API:
The code first instantiates the Boto3 client using the bedrock-runtime service name. The Lambda function receives the SNS event and parses it using the Python JSON library. The parsed contents are stored in the sns_event dictionary. The code creates a Amazon Bedrock Messages API style prompt with role and content attributes:
The content attribute’s value comes from the sns_event["message"] attribute in the SNS event. Refer to the converse_stream Boto3 API documentation for list of role values.
The converse_stream API accepts modelId and messages parameters. The value of modelId comes from an environment variable set on the Lambda function. The messages parameter is of type dictionary, and it must only contain Amazon Bedrock Messages API style prompts.
When the converse_stream API successfully runs, it returns an object that the Lambda code further analyzes to send partial tokens to the frontend:
As the LLM generates a token in response to the prompt it received, Lambda first sends DEFAULT_STREAM_START_TOKEN to the frontend using the AWS AppSync mutation operation. This token is a mechanism to alert the frontend to start rendering tokens. As the Lambda function receives chunks from the converse_stream API, it calls the AWS AppSync mutation operation, sending a partial token to the frontend to render.
To improve the user experience and reduce network overhead, the Lambda function doesn’t invoke the AWS AppSync mutation operation for every chunk it receives from the Amazon Bedrock converse_stream API. Instead, the Lambda code buffers partial tokens and invokes the AWS AppSync mutation operation after receiving five chunks. This avoids the overhead of AWS AppSync network calls, thereby reducing latency and improving the user experience.
After the Lambda function has finished sending the tokens, it sends DEFAULT_STREAM_END_TOKEN:
self.appsync.invoke_mutation(DEFAULT_STREAM_END_TOKEN)This token alerts the frontend that LLM streaming is complete.
For more details, refer to the GitHub repo. It contains a reference implementation of the Orchestrator Lambda function called bedrock-orchestrator-lambda.
Prerequisites
To deploy the solution, you must have the Terraform CLI installed in your environment. Complete all the steps in the Prerequisites section in the accompanying GitHub documentation.
Deploy the solution
Complete the following steps to deploy the solution:
- Open a command line terminal window.
- Change to the deployment folder.
- Edit the sample.tfvars file. Replace the variable values to match your AWS environment.
- Run the following commands to deploy the solution:
Detailed deployment steps are in the Deploy the solution section in the accompanying GitHub repository.
Test the solution
To test the solution, use the provided sample web UI and run it inside VS Code. For more information, refer to accompanying README documentation.
Clean up
Use the following code to clean your AWS environment from the resources deployed in the previous section. You must use the same sample.tfvars that you used to deploy the solution.
Conclusion
This post demonstrated how integrating an Amazon Bedrock streaming API with AWS AppSync subscriptions significantly enhances AI assistant responsiveness and user satisfaction. By implementing this streaming approach, the global financial services organization reduced initial response times for complex queries by approximately 75%—from 10 seconds to just 2–3 seconds—empowering users to view responses as they’re generated rather than waiting for complete answers. The business benefits are clear: reduced abandonment rates, improved user engagement, and a more responsive AI experience. Organizations can quickly implement this solution using the provided Lambda and Terraform code, quickly bringing these improvements to their own environments.
For even greater flexibility, AWS AppSync Events offers an alternative implementation pattern that can further enhance real-time capabilities using a fully managed WebSocket API. By addressing the fundamental tension between comprehensive AI responses and speed, this streaming approach enables organizations to maintain high-quality interactions while delivering the responsive experience modern users expect.
About the authors
 Salman Moghal, a Principal Consultant at AWS Professional Services Canada, specializes in crafting secure generative AI solutions for enterprises. With extensive experience in full-stack development, he excels in transforming complex technical challenges into practical business outcomes across banking, finance, and insurance sectors. In his downtime, he enjoys racquet sports and practicing Funakoshi Genshin’s teachings at his martial arts dojo.
Salman Moghal, a Principal Consultant at AWS Professional Services Canada, specializes in crafting secure generative AI solutions for enterprises. With extensive experience in full-stack development, he excels in transforming complex technical challenges into practical business outcomes across banking, finance, and insurance sectors. In his downtime, he enjoys racquet sports and practicing Funakoshi Genshin’s teachings at his martial arts dojo.
 Philippe Duplessis-Guindon is a cloud consultant at AWS, where he has worked on a wide range of generative AI projects. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. After earning his bachelor’s degree in software engineering and a master’s in computer vision and machine learning from Polytechnique Montreal, Philippe joined AWS to put his expertise to work for customers. When he’s not at work, you’re likely to find Philippe outdoors—either rock climbing or going for a run.
Philippe Duplessis-Guindon is a cloud consultant at AWS, where he has worked on a wide range of generative AI projects. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. After earning his bachelor’s degree in software engineering and a master’s in computer vision and machine learning from Polytechnique Montreal, Philippe joined AWS to put his expertise to work for customers. When he’s not at work, you’re likely to find Philippe outdoors—either rock climbing or going for a run.



