


Vehicle data is critical for original equipment manufacturers (OEMs) to drive continuous product innovation and performance improvements and to support new value-added services. Similarly, the increasing digitalization of vehicle architectures and adoption of software-configurable functions allow OEMs to add new features and capabilities efficiently. Sonatus’s Collector AI and Automator AI products address these two aspects of the move towards Software-Defined Vehicles (SDVs) in the automotive industry.
Collector AI lowers the barrier to using data across the entire vehicle lifecycle using data collection policies that can be created without changes to vehicle electronics or requiring modifications to embedded code. However, OEM engineers and other consumers of vehicle data struggle with the thousands of vehicle signals to choose to drive their specific use cases and outcomes. Likewise, Automator AI’s no-code methodology for automating vehicle functions using intuitive if-then-style scripted workflows can also be challenging, especially for OEM users who aren’t well-versed in the events and signals available on vehicles to incorporate in a desired automated action.
To address these challenges, Sonatus partnered with the AWS Generative AI Innovation Center to develop a natural language interface to generate data collection and automation policies using generative AI. This innovation aims to reduce the policy generation process from days to minutes while making it accessible to both engineers and non-experts alike.
In this post, we explore how we built this system using Sonatus’s Collector AI and Amazon Bedrock. We discuss the background, challenges, and high-level solution architecture.
Collector AI and Automator AI
Sonatus has developed a sophisticated vehicle data collection and automation workflow tool, which comprises two main products:
- Collector AI – Gathers and transmits precise vehicle data based on configurable trigger events
- Automator AI – Executes automated actions within the vehicle based on analyzed data and trigger conditions
The current process requires engineers to create data collection or automation policies manually. Depending on the range of an OEM’s use cases, there could be hundreds of policies for a given vehicle model. Also, identifying the correct data to collect for the given intent required sifting through multiple layers of information and organizational challenges. Our goal was to develop a more intelligent and intuitive way to accomplish the following:
- Generate policies from the user’s natural language input
- Significantly reduce policy creation time from days to minutes
- Provide complete control over the intermediate steps in the generation process
- Expand policy creation capabilities to non-engineers such as vehicle product owners, product planners, and even procurement
- Implement a human-in-the-loop review process for both existing and newly created policies
Key challenges
During implementation, we encountered several challenges:
- Complex event structures – Vehicle models and different policy entities use diverse representations and formats, requiring flexible policy generation
- Labeled data limitations – Labeled data mapping natural language inputs to desired policies is limited
- Format translation – The solution must handle different data formats and schemas across customers and vehicle models
- Quality assurance – Generated policies must be accurate and consistent
- Explainability – Clear explanations for how policies are generated can help build trust
Success metrics
We defined the following key metrics to measure the success of our solution:
- Business metrics:
- Reduced policy generation time
- Increased number of policies per customer
- Expanded user base for policy creation
- Technical metrics:
- Accuracy of generated policies
- Quality of results for modified prompts
- Operational metrics:
- Reduced policy generation effort and turnaround time compared to manual process
- Successful integration with existing systems
Solution overview
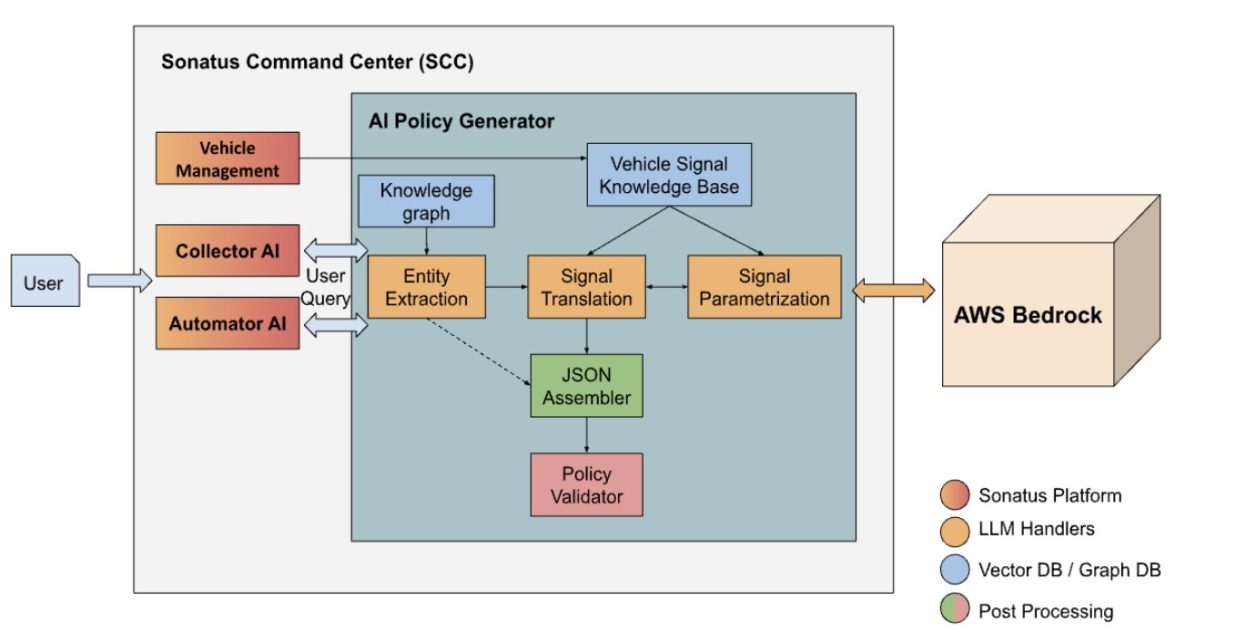
The Sonatus Advanced Technology team and Generative AI Innovation Center team built an automated policy generation system, as shown in the following diagram.

This is a chain of large language models (LLMs) that perform individual tasks, including entity extraction, signal translation, and signal parametrization.
Entity extraction
A fully generated vehicle policy consists of multiple parts, which could be captured within one single user statement. These are triggers and target data for collector policies, and triggers, actions, and associated tasks for automator policies. The user’s statement is first broken down into its entities using the following steps and rules:
- Few-shot examples are provided for each entity
- Trigger outputs must be self-contained with the appropriate signal value and comparison operator information:
- Query example: “Generate an automation policy that locks the doors automatically when the car is moving”
- Trigger output:
vehicle speed above 0, vehicle signal
- Triggers and actions are secondarily verified using a classification prompt
- For Automator AI, triggers and actions must be associated with their corresponding tasks
- The final output of this process is the intermediate structured XML representation of the user query in natural language:
- Query example: “Generate an automation policy that locks the doors automatically when the car is moving”
- Generated XML:
The following is a diagram of our improved solution, which converts a user query into XML output.

Signal translation and parametrization
To get to the final JSON policy structure from the intermediate structured XML output, the correct signals must be identified, the signal parameters need to be generated, and this information must be combined to follow the application’s expected JSON schema.
The output signal format of choice at this stage is Vehicle Signal Specification (VSS), an industry-standard specification driven by COVESA. VSS is a standard specifying vehicle signal naming conventions and strategies that make vehicle signals descriptive and understandable when compared to their physical Control Area Network (CAN) signal counterparts. This makes it not only suitable but also essential in the generative AI generation process because descriptive signal names and availability of their meanings are necessary.
The VSS signals, along with their descriptions and other necessary metadata, are embedded into a vector index. For every XML structure requiring a lookup of a vehicle signal, the process of signal translation includes the following steps:
- Available signal data is preprocessed and stored into a vector database.
- Each XML representation—triggers, actions, and data—is converted into their corresponding embeddings. In some cases, the XML phrases can also be enhanced for better embedding representation.
- For each of the preceding entities:
- Top-k similar vector embeddings are identified (assume k as 20).
- Candidate signals are reranked based on name and descriptions.
- The final signal is selected using a LLM selection prompt.
- In the case of triggers, after the selection of the correct signal, the trigger value and condition comparator operator are also generated using few-shot examples.
- This retrieved and generated information is combined into a predefined trigger, action, data, and task JSON object structure.
- Individual JSON objects are assembled to construct the final JSON policy.
- This is run through a policy schema validator before it is saved.
The following diagram illustrates the step-by-step process of signal translation. To generate the JSON output from the intermediate XML structure, correct signals are identified using vector-based lookups and reranking techniques.

Solution highlights
In this section, we discuss key components and features of the solution.
Improvement of task adjacency
In automator policies, a task is a discrete unit of work within a larger process. It has a specific purpose and performs a defined set of actions—both within and outside a vehicle. It also optionally defines a set of trigger conditions that, when evaluated to be true, the defined actions start executing. The larger process—the workflow—defines a dependency graph of tasks and the order in which they are executed. The workflow follows the following rules:
- Every automator policy starts with exactly one task
- A task can point to one or more next tasks
- One task can only initiate one other task
- Multiple possible next tasks can exist, but only one can be triggered at a time
- Each policy workflow runs one task at a given time
- Tasks can be arranged in linear or branching patterns
- If none of the conditions satisfy, the default is monitoring the trigger conditions for the next available tasks
For example:
*Loops back to start.
In some of the generated outputs, we identified that there can be two adjacent tasks in which one doesn’t have an action, and another doesn’t have a trigger. Task merging aims to resolve this issue by merging those into a single task. To address this, we implemented task merging using Anthropic’s Claude on Amazon Bedrock. Our outcomes were as follows:
- Solve the task merging issue, where multiple tasks with incomplete information are merged into one task
- Properly generate tasks that point to multiple next tasks
- Change the prompt style to decision tree-based planning to make it more flexible
Multi-agent approach for parameter generation
During the signal translation process, an exhaustive list of signals is fed into a vector store, and when corresponding triggers or actions are generated, they are used to search the vector store and select the signal with the highest relevancy. However, this sometimes generates less accurate or ambiguous results.
For example, the following policy asks to cool down the car:
Action:
The corresponding signal should try to cool the car cabin, as shown in the following signal:
Vehicle.Cabin.HVAC.Station.Row1.Driver.Temperature
It should not cool the car engine, as shown in the following incorrect signal:
Vehicle.Powertrain.CombustionEngine.EngineCoolant.Temperature
We mitigated this issue by introducing a multi-agent approach. Our approach has two agents:
- ReasoningAgent – Proposes initial signal names based on the query and knowledge base
- JudgeAgent – Evaluates and refines the proposed signals
The agents interact iteratively up to a set cycle threshold before claiming success for signal identification.
Reduce redundant LLM calls
To reduce latency, parts of the pipeline were identified that could be merged into a single LLM call. For example, trigger condition value generation and trigger condition operator generation were individual LLM calls.We addressed this by introducing a faster Anthropic’s Claude 3 Haiku model and merging prompts where it is possible to do so. The following is an example of a set of prompts before and after merging.The first example is before merging, with the trigger set to when the temperature is above 20 degrees Celsius:
The following is the combined response for the same trigger:
Context-driven policy generation
The goal here is to disambiguate the signal translation, similar to the multi-agent approach for parameter generation. To make policy generation more context-aware, we proposed a customer intent clarifier that carries out the following tasks:
- Retrieves relevant subsystems using knowledge base lookups
- Identifies the intended target subsystem
- Allows user verification and override
This approach works by using external and preprocessed information like available vehicle subsystems, knowledge bases, and signals to guide the signal selection. Users can also clarify or override intent in cases of ambiguity early on to reduce wasted iterations and achieve the desired result more quickly. For example, in the case of the previously stated example on an ambiguous generation of “cool the car,” users are asked to clarify which subsystem they meant—to choose from “Engine” or “Cabin.”
Conclusion
Combining early feedback loops and a multi-agent approach has transformed Sonatus’s policy creation system into a more automated and efficient solution. By using Amazon Bedrock, we created a system that not only automates policy creation, reducing time taken by 70%, but also provides accuracy through context-aware generation and validation. So, organizations can achieve similar efficiency gains by implementing this multi-agent approach with Amazon Bedrock for their own complex policy creation workflows. Developers can leverage these techniques to build natural language interfaces that dramatically reduce technical complexity while maintaining precision in business-critical systems.
About the authors
 Giridhar Akila Dhakshinamoorthy is the Senior Staff Engineer and AI/ML Tech Lead in the CTO Office at Sonatus.
Giridhar Akila Dhakshinamoorthy is the Senior Staff Engineer and AI/ML Tech Lead in the CTO Office at Sonatus.
 Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services who helps customers solve their business problems using generative AI and machine learning. He has done MS with Thesis in Machine Learning from University of Illinois and has extensive experience in solving customer problem in the field of data science.
Tanay Chowdhury is a Data Scientist at Generative AI Innovation Center at Amazon Web Services who helps customers solve their business problems using generative AI and machine learning. He has done MS with Thesis in Machine Learning from University of Illinois and has extensive experience in solving customer problem in the field of data science.
 Parth Patwa is a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He has co-authored research papers at top AI/ML venues and has 1000+ citations.
Parth Patwa is a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He has co-authored research papers at top AI/ML venues and has 1000+ citations.
 Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications.
Yingwei Yu is an Applied Science Manager at Generative AI Innovation Center, AWS, where he leverages machine learning and generative AI to drive innovation across industries. With a PhD in Computer Science from Texas A&M University and years of working experience, Yingwei brings extensive expertise in applying cutting-edge technologies to real-world applications.
 Hamed Yazdanpanah was a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He helps customers solve their business problems using generative AI and machine learning.
Hamed Yazdanpanah was a Data Scientist in the Generative AI Innovation Center at Amazon Web Services. He helps customers solve their business problems using generative AI and machine learning.



