


AI assistants that forget what you told them 5 minutes ago aren’t very helpful. While large language models (LLMs) excel at generating human-like responses, they are fundamentally stateless—they don’t retain information between interactions. This forces developers to build custom memory systems to track conversation history, remember user preferences, and maintain context across sessions, often solving the same problems repeatedly across different applications.
At the AWS Summit New York City 2025, we introduced Amazon Bedrock AgentCore Memory, a service for agent memory management. AgentCore Memory makes it easy for developers to build context-aware agents by eliminating complex memory infrastructure management while providing full control over what the AI agent remembers. It provides powerful capabilities for maintaining both short-term working memory (capturing immediate conversation context within a session) and long-term intelligent memory (storing persistent insights and preferences across sessions), so AI agents can retain context, learn from interactions, and deliver truly personalized experiences.
AgentCore Memory transforms one-off conversations into continuous, evolving relationships between users and AI agents. Instead of repeatedly asking for the same information (“What’s your account number?”) or forgetting critical preferences (“I’m allergic to shellfish”), agents can maintain context and build upon previous interactions naturally. AgentCore Memory seamlessly integrates with other agent-building tools, so that developers can enhance existing agents with persistent memory capabilities without managing complex infrastructure. Unlike do-it-yourself memory solutions that require developers to manually orchestrate multiple components—raw conversation storage, vector databases, session caching systems, and custom retrieval logic—AgentCore Memory offers a fully managed service with built-in storage, intelligent extraction and efficient retrieval.
In this blog post, we explore the specific challenges that AgentCore Memory solves, introduce its core concepts, and share best practices.
The memory problem in AI agents
The ability to remember is the foundation of meaningful human relationships. We remember past conversations, learn preferences over time, and build shared context that deepens our connections. Developers building AI agents have traditionally faced significant technical challenges implementing these same fundamental capabilities, creating a substantial gap between human-like understanding and machine interactions.
When implementing memory for AI agents, developers encounter several fundamental challenges:
- Context window constraints: Modern LLMs have limited capacity to process conversation history. Developers must implement context window management strategies (often manually pruning or summarizing earlier exchanges) to handle ongoing customer conversations to stay within token limits.
- State management complexity: Without dedicated memory systems, developers often build custom solutions for tracking conversation history, user preferences, and agent state—reinventing similar solutions across projects.
- Memory recall challenges: Storing raw conversation data isn’t enough. Without intelligent extraction and structured memory organization, developers must implement complex systems to identify and surface relevant information at the right time.
- Persistence without intelligence: Most existing solutions focus on data storage rather than intelligent memory formation, providing no built-in mechanisms to extract relevant insights or identify patterns that matter to users.
These limitations don’t just create technical hurdles—they fundamentally impact user experience, for example:
- A financial advisor agent losing context about a user’s retirement goals and strategies discussed earlier in the same session
- A coding assistant lacking access to previously established user programming style preferences or setup details
Without effective memory implementation, conversations become disjointed and repetitive rather than continuous and evolving. This creates unnecessary back-and-forth interactions that increase costs and latency while frustrating the users.
Introducing Amazon Bedrock AgentCore Memory
Amazon Bedrock AgentCore Memory is a fully managed service that lets your AI agents deliver intelligent, context-aware, and personalized interactions by maintaining both immediate and long-term knowledge. The service is built on five key design principles:
- Abstracted storage: AgentCore Memory handles the storage complexity for short- and long-term information, without requiring developers to manage underlying infrastructures.
- Security: Encrypted data both at rest and in transit.
- Continuity: Events within sessions are stored in chronological order to maintain accurate narrative flow and context.
- Data organization and access control: Hierarchical namespaces provide structured memory organization and fine-grained access control for shared memory contexts.
- Scalability and performance: Efficiently handle large volumes of memory data with low latency, facilitating fast and reliable retrieval as usage grows.
The service seamlessly integrates with other services in Bedrock AgentCore, such as AgentCore Runtime and AgentCore Observability. It combines API-first design with pre-verified defaults, so developers can quickly implement basic memory capabilities while retaining extensibility for advanced scenarios.
Core components of AgentCore Memory
AgentCore Memory consists of several key components that work together to provide both short-term context and long-term intelligence for your agents.
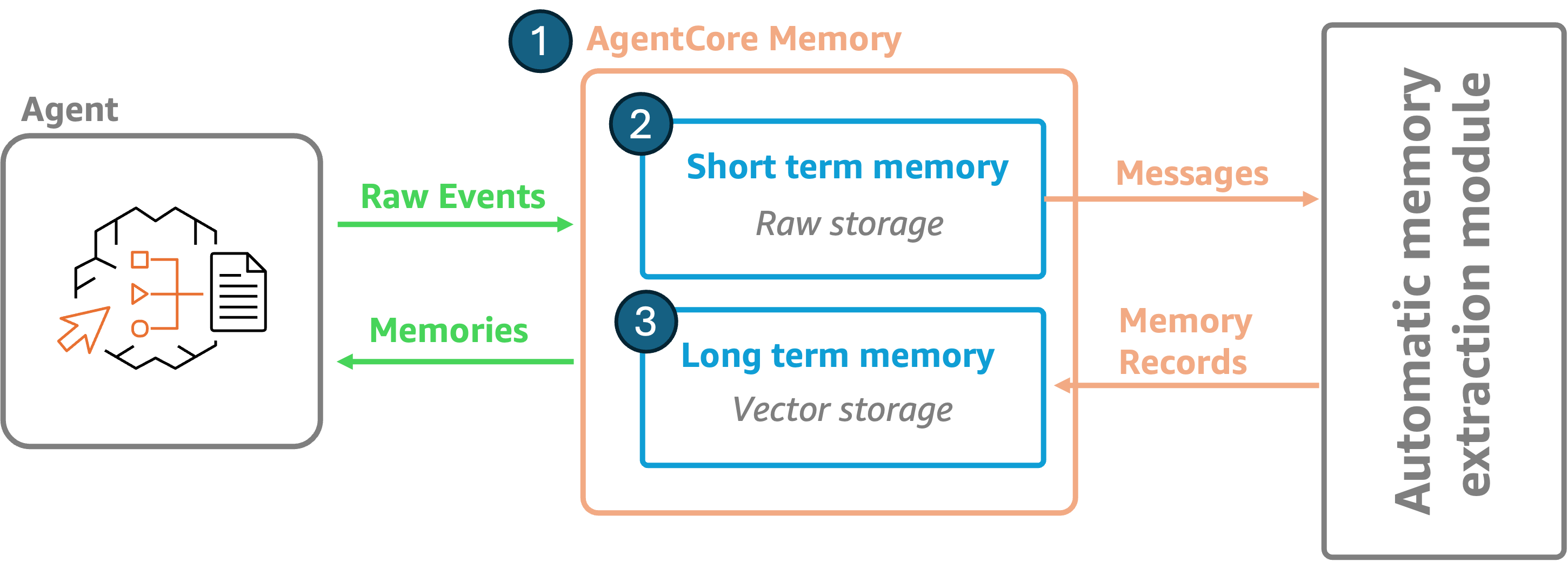
Let’s explore each component (shown in the preceding figure) with examples of how they function in practice.
1. AgentCore Memory resource
A memory resource is a logical container within AgentCore Memory that encapsulates both raw events and processed long-term memories. Think of a memory resource as the foundation of your agent’s memory system—it defines how long data is retained, how it’s secured, and how raw interactions are transformed into meaningful insights.
When creating a memory resource, you can specify an event expiry duration (up to 365 days) to control how long raw conversation data is retained in short-term memory. Data within AgentCore Memory is encrypted both at rest and in transit. By default, AWS managed keys are used for this encryption, but you can choose to enable encryption with your own customer managed KMS keys for greater control.
2. Short-term memory
Short-term memory captures raw interaction data as immutable events, organized by actor and session. This organization supports structured storage of conversations between users and agents, system events, state changes, and other interaction data. It takes in events and stores them synchronously in the AgentCore Memory resource. These events can be either “Conversational” (USER/ASSISTANT/TOOL or other message types) or “blob” (contains binary content that can be used to store checkpoints or agent state). Out of the two event types, only the Conversational events are used for long-term memory extraction.
To create an event, you typically need 3 identifiers.
memoryId:This is automatically created and returned in the response when you create a new memory resource.actorId:which typically identifies entities in your system (users, agents, project, or combinations),sessionId:groups related events together.
This hierarchical structure enables precise retrieval of relevant conversation context without loading unrelated data. Let’s explore how to create a memory resource for a customer support agent using Boto3 client:
# Creating a new memory resource
response = agentcore_client.create_memory(
name="CustomerSupportMemory",
description="Memory store for our customer support agent",
eventExpiryDuration=30, # Store raw events for 30 days
encryptionKeyArn="arn:aws:kms:us-east-1:123456789012:key/abcd1234-...", # Optional customer-managed KMS key
)
# Storing a user message as an event
response = agentcore_client.create_event(
memoryId="mem-123abcd",
actorId="customer-456",
sessionId="session-789",
eventTimestamp=int(time.time() * 1000),
payload=[
{
"conversational": {
"content": {"text": "I'm looking for a waterproof camera under $300"},
"role": "USER"
}
}
]
)
# Retrieving recent conversation history
events = agentcore_client.list_events(
memoryId="mem-123abcd",
actorId="customer-456",
sessionId="session-789",
maxResults=10,
)
3. Long-term memory
Long-term memory contains extracted insights, preferences, and knowledge derived from raw events. Unlike short-term memory, which stores verbatim data, long-term memory captures meaningful information that persists across sessions—such as user preferences, conversation summaries, and key insights.
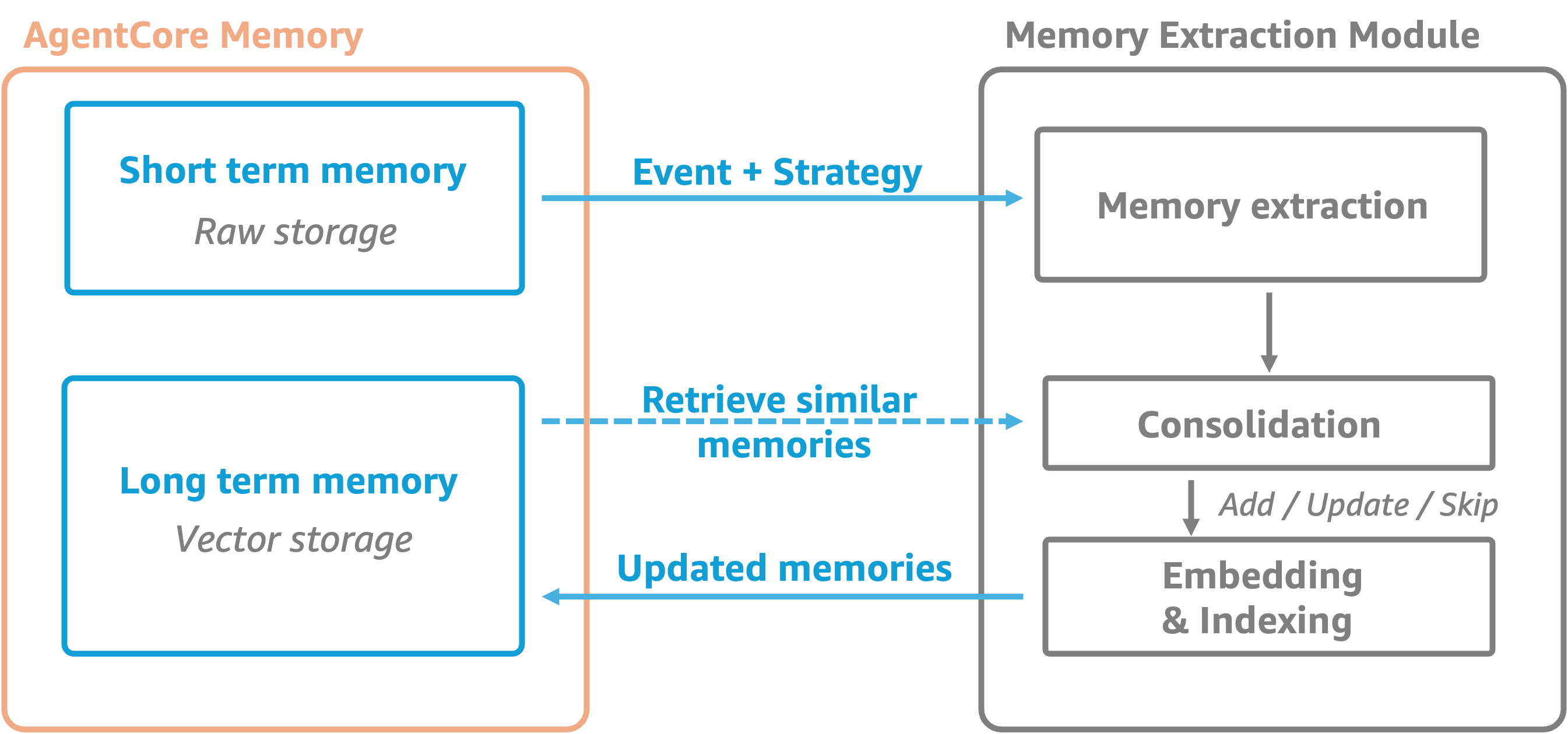
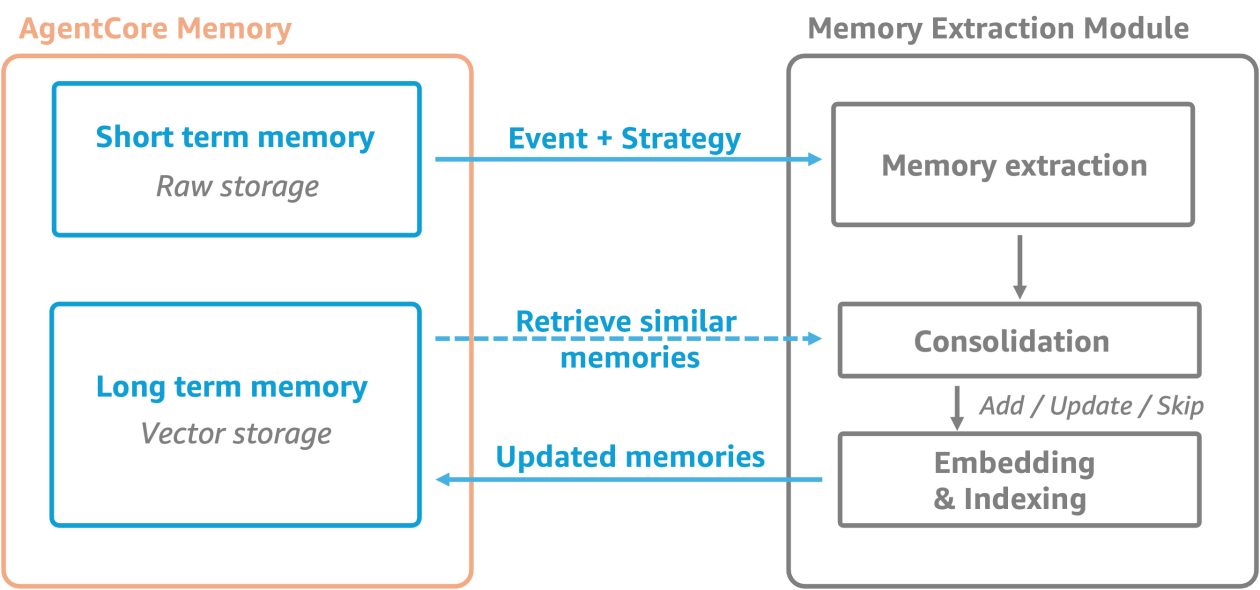
The extraction process happens asynchronously after events are created, using the memory strategies defined within your memory resource. This managed asynchronous process extracts and consolidates long term memory records for efficient retrieval.
Let’s explore how to create the long-term memory resource for the customer support agent we saw before:
# Creating a new memory resource with long term
response = agentcore_client.create_memory(
name="CustomerSupportMemory",
description="Memory store for our customer support agent",
eventExpiryDuration=30, # Store raw events for 30 days
encryptionKeyArn="arn:aws:kms:us-east-1:123456789012:key/abcd1234-...", # Optional customer-managed KMS key
memoryStrategies=[{
"userPreferenceMemoryStrategy": {
"name": "UserPreferences",
"namespaces": ["customer-support/{actorId}/preferences"]
}
}]
)
3.a Namespaces
Namespaces are a critical organizational concept within long-term memory that provide hierarchical structure within your memory resource. They function like file system paths, and you can use them to logically group and categorize memories. These are especially powerful in multi-tenant systems, be it multi-agent, multi-users, or both. Namespaces serve several important purposes:
- Organizational structure: Separate different types of memories (preferences, summaries, entities) into distinct logical containers
- Access control: Control which memories are accessible to different agents or in different contexts
- Multi-tenant isolation: Segregate memories for different users or organizations with patterns like
/org_id/user_id/preferences - Focused retrieval: Query specific types of memories without searching through unrelated information
For example, you might structure namespaces like:
/retail-agent/customer-123/preferences: For a specific customer’s preferences/retail-agent/product-knowledge: For shared product information accessible to users/support-agent/customer-123/case-summaries/session-001: For summaries of past support cases
The dynamic namespace creation above uses special placeholder variables in your namespace definitions:
{actorId}: Uses the actor identifier from the events being processed{sessionId}: Uses the session identifier from the events{strategyId}: Uses the strategy identifier for organization
This allows for elegant namespace structuring without hardcoding identifiers. When retrieving memories, you specify the exact namespace to search within, or a prefix match:
# Retrieving relevant memory records using semantic search
memories = agentcore_client.retrieve_memory_records(
memoryId="mem-12345abcdef",
namespace="customer-support/user-1/preferences",
searchCriteria={
"searchQuery": "Which camera should I buy?",
"topK": 5
}
)3.b Memory strategies
Memory strategies define the intelligence layer that transforms raw events into meaningful long-term memories. They determine what information should be extracted, how it should be processed, and where the resulting memories should be stored. Each strategy is configured with a specific namespace where the extracted memories will be stored and consolidated, creating a clear organizational structure for different types of memories. All strategies by default ignore personally identifiable information (PII) data from long-term memory records. AgentCore Memory provides 3 built-in strategies:
- Semantic Strategy: Stores facts and knowledge mentioned in the conversation for future reference. For example, “The customer’s company has 500 employees across 3 office locations in Seattle, Austin, and Boston.”
- Summary Strategy: Stores a running summary of a conversation, capturing main points and decisions, scoped to a session. For example, “Customer inquired about enterprise pricing, discussed implementation timeline requirements, and requested a follow-up demo.”
- User Preferences Strategy: Stores user preferences, choices, or styles. For example, “User prefers detailed technical explanations over high-level summaries”, “User prefers Python for development work”.
Here are some examples of built-in memory strategies that are defined at the time of creating an AgentCore Memory resource:
# defining Memory Strategies
strategies = [{
"semanticMemoryStrategy": {
"name": "semantic-facts",
"namespaces": ["/customer/{actorId}/facts"],
},
"summaryMemoryStrategy": {
"name": "conversation-summary",
"namespaces": ["/customer/{actorId}/{sessionId}/summary"],
},
"userPreferenceMemoryStrategy": {
"name": "user-preferences",
"namespace": ["/customer/{actorId}/preferences"],
}
]To allow flexibility, Bedrock AgentCore also offers Custom memory strategies that lets you choose a specific LLM and override the prompt for extraction and consolidation to your specific domain or use case. For example, you might want to append to the semantic memory prompt so that it only extracts specific types of facts or memories.
Now that we understand the key components, here’s what the overall AgentCore Memory architecture looks like:
 These components work together seamlessly to provide a comprehensive memory system for your AI agents, enabling them to maintain immediate context while building meaningful long-term understanding of user interactions and preferences.
These components work together seamlessly to provide a comprehensive memory system for your AI agents, enabling them to maintain immediate context while building meaningful long-term understanding of user interactions and preferences.
Advanced features
Beyond the core memory capabilities, Amazon Bedrock AgentCore Memory offers advanced features that enable complex agent workflows and enhanced user experiences.
Branching
Branching allows agents to create alternative conversation paths from a specific point in the event history. Think of branching like creating a fork in the road—the conversation can continue down multiple different paths from the same starting point. This powerful feature supports several advanced use cases:
- Message editing: When users edit their previous messages, branching preserves both the original conversation flow and the new direction. The agent maintains coherent context even when earlier inputs change.
- What-if scenarios: Agents can explore hypothetical paths in decision-making processes without losing the main conversation thread. For example, a financial advisor agent could explore different investment strategies while keeping the original consultation intact.
- Alternative approaches: For complex problem-solving, agents can maintain multiple solution approaches simultaneously, allowing users to compare different options side-by-side.
Branching works by creating a new named branch within the existing memory resource, using the same actor_id and session_id. When creating a branched event, you specify a branch name and the rootEventId from which the branch originates. This allows for alternative conversation paths without the need for new actor or session identifiers. For example:
{
"memoryId": "mem-12345abcdef",
"actorId": "/agent-support-123/customer-456",
"sessionId": "session-789",
"eventTimestamp": 1718806000000,
"payload": [
{
"conversational": {
"content": {"text": "I'm looking for a waterproof action camera for extreme sports."},
"role": "USER"
}
}
],
"branch": {
"name": "edited-conversation",
"rootEventId": "evt-67890"
}
}
This approach allows the agent to manage multiple conversation paths within the same memory resource, providing powerful conversation management capabilities.
Checkpointing
With checkpointing, agents can save and mark specific states in the conversation, creating reference points that can be returned to later. This is like saving your progress in a complex game or application. This feature is particularly valuable for:
- Multi-session tasks: Break complex tasks across multiple sessions while preserving context. Users can return days or weeks later and the agent can resume exactly where they left off.
- Workflow resumption: With workflow resumption, users can pause complex processes (like mortgage applications or travel planning) and resume them seamlessly without starting over or repeating information.
- Conversation bookmarks: Mark important decision points that might need to be referenced later, such as when a user selects specific preferences or makes key decisions.
Checkpoints can be implemented through raw events under a different isolation (actor and session), which can later be retrieved through the GetEvent API. The blob payload type can be used to ingest data that can be in various formats and doesn’t necessarily have to be conversational. Note that these events will be ignored for long term memory extraction. These advanced features extend the capabilities of AgentCore Memory beyond simple context retention, enabling sophisticated agent experiences that better approximate human-like memory and conversation management. By incorporating branching and checkpointing into your agent design, you can create more natural, flexible, and personalized user interactions.
Best practices
Optimization of memories across your agentic system should work backwards from each agent’s core objectives. How and when an agent remembers something should have these objectives in mind.
1. Structured memory architecture
Design your memory architecture intentionally by implementing distinct memory types for different needs. Use short-term memory for immediate conversational context and long-term memory for persistent knowledge and user preferences. Organize memories using hierarchical namespaces (for example, /org_id/user_id/preferences) for precise memory isolation and retrieval. Consider appropriate time-to-live (TTL) settings based on your application’s requirements and data privacy policies. For instance, support chat histories might be retained for 30 days, while persistent customer preferences might be kept for much longer.
2. Memory strategies
The effectiveness of long-term memory depends greatly on your memory strategies. Use built-in strategies for common needs like user preference extraction and conversation summarization, but don’t hesitate to build on top of these by using custom strategies for your specific use cases. For defining custom memory strategies, focus on extracting only the relevant information that directly supports your agent’s objectives. For example, a travel booking agent should prioritize extracting travel preferences, important dates, and budget constraints.
3. Efficient memory operations
Implement a rhythm of memory operations that balances performance with contextual awareness:
- Retrieve relevant memories from within each user interaction for context hydration
- Use targeted retrieval methods (list events for recent raw context, summaries for session context, semantic search for related long term memory records)
- Store new interactions promptly using the
CreateEventAPI to maintain accurate history
Be aware that long-term memory extraction and consolidation is an asynchronous process, which leads to refresh delays when ingesting new information into long-term memory. For time-sensitive applications, plan accordingly by implementing appropriate caching, session handling, and combined context hydration techniques.
4. Security and privacy considerations
Memory often contains sensitive information, so implement proper security measures:
- Use actors and namespaces properly to organize data
- Use AWS Identity and Access Management (IAM)-based access controls to implement least-privileged controls for memory resource access
- Consider privacy implications when storing personal information, and follow relevant compliance requirements for data retention
- Use customer managed KMS keys for encryption of highly sensitive data
- Implement guardrails to prevent prompt injection and memory poisoning
5. Observability
Maintain visibility into your memory systems by using built-in event tracking and logging for memory operations. Monitor memory extraction patterns to verify they’re capturing the right information and track the effectiveness of your memory strategies. Periodically review and adjust your memory architecture based on agent performance metrics and evolving use case requirements. The key is to balance comprehensive memory retention with efficient resource utilization while maintaining focus on your agent’s core objectives.
Conclusion
Amazon Bedrock AgentCore Memory provides a comprehensive solution to one of the most challenging aspects of building effective AI agents—maintaining context and learning from interactions. By combining flexible short-term event storage with intelligent long-term memory extraction using AgentCore Memory, you can create more personalized, contextual, and helpful AI experiences without managing complex memory infrastructure. The service’s hierarchical namespaces, customizable memory strategies, and advanced features provide the foundations for sophisticated agent behaviors that feel more natural and human-like.
To get started on AgentCore Memory, visit the following resources:
About the authors
 Akarsha Sehwag is a WW Generative AI Data Scientist for Amazon Bedrock – Agents GTM team. With over six years of expertise in AI/ML product development, she has built enterprise solutions across diverse customer segments.
Akarsha Sehwag is a WW Generative AI Data Scientist for Amazon Bedrock – Agents GTM team. With over six years of expertise in AI/ML product development, she has built enterprise solutions across diverse customer segments.
 Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
Dani Mitchell is a Generative AI Specialist Solutions Architect at Amazon Web Services (AWS). He is focused on helping accelerate enterprises across the world on their generative AI journeys with Amazon Bedrock.
 Mani Khanuja is a Principal Generative AI Specialist SA, author of the book Applied Machine Learning and High-Performance Computing on AWS. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Principal Generative AI Specialist SA, author of the book Applied Machine Learning and High-Performance Computing on AWS. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
 Gopikrishnan Anilkumar is a Principal Technical Product Manager in Amazon. He has over 10 years of product management experience across a variety of domains and is passionate about AI/ML.
Gopikrishnan Anilkumar is a Principal Technical Product Manager in Amazon. He has over 10 years of product management experience across a variety of domains and is passionate about AI/ML.
 Noor Randhawa is a Software Engineering Lead on AgentCore Memory at Amazon Web Services (AWS).
Noor Randhawa is a Software Engineering Lead on AgentCore Memory at Amazon Web Services (AWS).



