



This post is co-written with Michelle Tat, Christopher Penrose, Rasmus Buchmann, and Daniel Hansen from Care Access.
Organizations operating in the healthcare industry face a critical challenge as they process large volumes of medical records and face a critical challenge: how to efficiently analyze thousands of medical records daily while maintaining strict security and compliance standards. LLM-based medical record analysis is a powerful solution but requires reprocessing substantial portions of medical data for each separate analysis question, leading to high operational costs and slower response times.
One organization that faced this challenge head-on was Care Access, a global health services and clinical research leader, who encountered this exact challenge when scaling their health screening program. Processing 300-500+ medical records daily required multiple separate prompts for each analysis, with each prompt reprocessing substantial portions of the medical record. With hundreds of new participants choosing to share their medical records daily, Care Access needed a solution that could scale efficiently while maintaining strict healthcare compliance and privacy standards.
The prompt caching feature in Amazon Bedrock provided the breakthrough. By caching the static medical record content while varying only the analysis questions, Care Access achieved significant cost reductions and faster processing times. This optimization transformed medical record processing from a potential constraint into an enabler of program growth.
In this post, we demonstrate how healthcare organizations can securely implement prompt caching technology to streamline medical record processing while maintaining compliance requirements.
Background
Care Access is working to make the future of health better for all. With hundreds of clinical research locations, mobile clinics, and clinicians across the globe, Care Access is bringing world-class health research and medical services directly to communities that often face barriers to care.
At the heart of their mission, they have a health screening program that provides participants results for advanced blood tests while facilitating connections to relevant health resources, including groundbreaking clinical trials. Care Access currently provides health screenings to nearly 15,000 new participants monthly worldwide and projects to grow rapidly in the coming months and years.
Participants often choose to share their medical records, enabling Care Access to provide more personalized medical oversight and identify potential health resources, including clinical research opportunities, that align with their health profiles. This innovative approach resonates strongly with participants, leading to hundreds of people requesting to share their medical records with Care Access each day.
However, rapid growth and success can bring about logistical challenges for organizations scaling their operations to quickly meet rising demand. For Care Access, processing vast amounts of diverse medical data formats while maintaining strict compliance, privacy, and security standards required an innovative solution. The company implemented a Large Language Model (LLM) solution using Amazon Bedrock to analyze these records. Though electronic medical records may follow some normalized data standards, the contents of each record can vary widely due to how information is recorded for each visit a patient makes to their physician. While traditional rule-based systems and OCR-based extraction methods exist, LLMs are particularly effective for this challenge because they can understand context and interpret variations in how medical information is documented across different healthcare providers, without requiring extensive rule customization for each data source format.
The initial implementation required multiple separate prompts for each analysis, with each prompt needing to reprocess substantial portions of the medical record. As the program scaled, this approach led to significant daily operational costs due to the high volume of input tokens being processed repeatedly.
Prompt caching overview
Before diving into Care Access’s implementation, it is important to understand Amazon Bedrock’s prompt caching capability and why it is particularly effective for medical record processing.
Prompt caching allows for the re-use of parts of a prompt that would otherwise be recomputed for every record upon inference. When using the prompt caching feature, Amazon Bedrock stores or caches the initial prompt (referred to as a prefix) and assigns it a unique promptId. As subsequent records are processed, the prompt prefix is retrieved from the cache via the promptId and is used for inference of each subsequent record.
When to use prompt caching vs. other optimization techniques
Prompt caching is one of several optimization techniques that can be used to drastically improve performance. Labeled component prompt caching can be used to cache the parts of prompts that will be static between requests, while still allowing parts of the prompt to vary. For Care Access, labeled component prompt caching exactly handled their use case. Other optimization techniques, such as question bundling, can also be layered in to further improve results.
Sample prompt structure showing cached vs. non-cached components
A participant’s medical record will stay static between requests, while the exact medical question asked about the record will change. This approach enables caching of a vast majority of the tokens, while allowing for variability in the final part of the prompt. For example:
{
"content": [
{
"cache-control": {
"type": "ephemeral"
},
"text": [
],
"type": "text"
},
{
"text": "The question is: ",
"type": "text"
}
]
}
Here, the caching of the participant’s medical record allows for quick iteration through a vast number of medical questions without reprocessing the majority of the tokens.
Solution architecture
Care Access’s decision to use Amazon Bedrock was rooted in their long-standing partnership with AWS, which had supported Care Access’s growth from a startup to a multinational enterprise. Patient privacy and security compliance remain the highest priority to Care Access, so it was key to only utilize and implement solutions that kept patient data safe. AWS solutions continually demonstrated through its history with Care Access their strict compliance to Care Access’s high security standards and privacy measures that ensure the safety of medical records data. The prompt caching feature in Amazon Bedrock provided a solution for Care Access to also optimize the speed and cost associated with processing thousands of medical records through an LLM.
The general architecture of the Care Access inference pipeline follows these numbered stages:
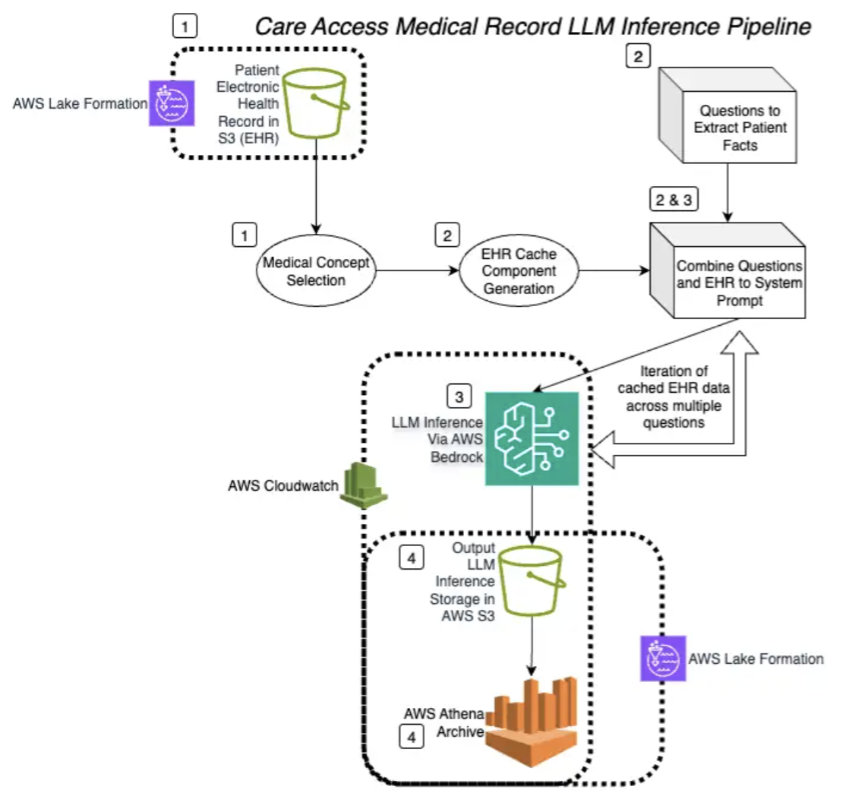
Stage 1: Medical record retrieval
Individual electronic health records (EHRs) are retrieved from an Amazon S3 bucket, normalized for processing, and prepared for inference with unnecessary data removed.
Stage 2: Prompt cache management
The medical record content becomes the static cached prefix, while specific analysis questions form the dynamic portion that varies with each query.
Stage 3: LLM inference
Each cached health record receives multiple analysis questions using Amazon Bedrock. Cache checkpointing activates when the prefix matches existing cache and exceeds the minimum 1,000 token requirement.
Stage 4: Output processing
Results are combined into a single JSON per participant and stored in Amazon S3 for downstream analytics via Amazon Athena. Participants are then matched to relevant clinical trials.
Implementation details
Care Access’s implementation processes medical records using a custom data schema based on a combination of their input data sources, each of which uses its own standard. The records consist of several sections, such as past health history, medications, and prior visits.
Data schema and format:
The following is a highly abbreviated example of a participant’s record structure:
{
participant_id: "6951cd6c-d166-47e4-9810-e19c5c5a140d",
participant_name: "Jane Doe",
participant_city: "Metropolis",
participant_state: "IL",
participant_address: "123 Lois Ln",
participant_zipcode: "55555-5555",
content: {
clinicals: {
careResources: {
organizations: {
{ resourceType: "Organization", name: "Metropolis General Hospital"}
},
practitioners: {
{ resourceType: "Practitioner", name: "Clark Kent"}
}
},
resourceGroups: {
medications: [
{ title: "Simvastatin 80 MG [Zocor]", subTitle: "active", IsActive: "Yes - status is 'active'" },
{ title: "Bupropion Hydrochloride 300 MG Extended Release Oral Tablet [Wellbutrin]", subTitle: "active", IsActive: "Yes - status is 'active'"}
],
encounters: [
{ title: "Office Visit", date: "2022-01-07T00:00:00.000", subTitle: ""},
{ title: "Emergency Department Visit", subTitle: "finished", date: "2022-06-24T19:03:45.352"}
],
conditions: [
{ title: "Type 2 Diabetes Mellitus", subTitle: "resolved", date: "2022-10-10T19:03:45.341"},
{ title: "Depression", subTitle: "resolved", date: "2007-08-10T19:03:45.351"}
],
diagnosticReports: [
{ title: "LabCorp - Hemoglobin A1c", subTitle: "preliminary", date: "2021-07-10T19:03:45.342"}
],
familyMemberHistory: [
{ title: "Maternal grandmother - Diabetes", subTitle: "completed"}
],
socialHistory: [
{ title: "Current smoker", subTitle: "final", date: "2022-01-10T19:03:45.344"}
]
}
}
}
}
Data security and privacy
Security and privacy requirements:
Care Access faces stringent requirements when processing medical records:
- High privacy and security standards compliance (HIPAA or HIPAA-like standards) compliance for all PHI handling
- Minimal necessary information principle
- Audit trail requirements for all data access
- Secure data transmission and storage
How these requirements are met:
Each EHR processed through the inference pipeline consists of personal health information (PHI) and personally identifying information (PII). Care Access addresses these requirements through:
- AWS Lake Formation: Manages privileged IAM permissions for all services (Amazon S3, Amazon Bedrock, Amazon Athena)
- Data Minimization: Following guidelines based on HIPAA compliance, only minimally necessary PHI (medical conditions) is used, with unnecessary PHI discarded
- PII Removal: All PII (names, addresses, phone numbers) are removed, retaining only unique identifiers for record indexing
- Audit Logging: Complete audit trails available through Amazon CloudWatch for all data and service access
Benefits and impacts
The implementation of prompt caching in Amazon Bedrock delivered transformative results:
Cost Optimization:
- 86% reduction in Amazon Bedrock costs (7x decrease)
Performance Improvements:
- 66% reduction in processing time per record (3x faster)
- 4-8+ hours of processing time saved daily
Operational benefits:
- Reduced token consumption through context reuse
- Improved response times for sequential queries
- Maintained context integrity across all medical record processing operations
- Met all implementation deadlines despite ambitious timelines
“AWS was a fantastic partner as we launched our first generation of LLM-powered solutions,” says Josh Brandoff, Head of Applied Machine Learning & Analytics at Care Access. “Amazon Bedrock quickly integrated with our existing data lake architecture and allowed us to launch our medical history review solution in six weeks (instead of several months) and identify and match more health resource opportunities, including clinical trials, for our health screening participants. When our record intake spiked sooner than predicted, the Bedrock prompt caching capability allowed us to manage costs with minimal technical changes.”
Best practices and technical considerations
Implementation recommendations:
Care Access’s team found the prompt caching feature highly flexible for their use case. Key learnings include:
- Token Threshold Strategy: Most EHRs contain thousands to tens of thousands of tokens. Using the 1,000-token minimum threshold, their pipeline automatically enabled caching when records were sufficiently large.
- Default Caching Approach: Enable caching by default when expected prompts vary in size, particularly when biased toward larger token counts.
- Cache Optimization: Structure prompts so medical record content (static, large) becomes the cached prefix, while analysis questions (dynamic, small) remain uncached.
Conclusion
Care Access successfully transformed its medical record processing challenge into a scalable capability and organizational strength. Through strategic implementation of Amazon Bedrock’s prompt caching capability, Care Access data processing achieved significant cost reductions and faster processing times while maintaining strict compliance and privacy standards.
This success demonstrates how choosing the right technology strategy can address immediate business challenges while supporting long-term mission objectives. For Care Access, this technical optimization enabled continued growth of their health screening program, connecting more communities with potentially life-changing health resources and clinical research opportunities.
For more information about working with prompt caching on Amazon Bedrock, see Prompt caching for faster model inference.
About Care Access
Care Access is working to make the future of health better for all. With hundreds of research locations, mobile clinics, and clinicians across the globe, we bring world-class research and health services directly to communities that often face barriers to care. We are dedicated to ensuring that every person has the opportunity to understand their health, access the care they need, and contribute to the medical breakthroughs of tomorrow.We put people at the heart of medical progress with programs like Future of Medicine, which makes advanced health screenings and research opportunities accessible to communities worldwide, and Difference Makers, which supports local leaders to expand their community health and wellbeing efforts. Through partnerships, technology, and perseverance, we are reimagining how clinical research and health services reach the world. Together, we are building a future of health that is better and more accessible for all.To learn more about Care Access, visit www.CareAccess.com.
About the authors
 Deepthi Paruchuri is a Senior Solutions Architect at AWS. With specialization in GenAI and Analytics domains, Deepthi works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.
Deepthi Paruchuri is a Senior Solutions Architect at AWS. With specialization in GenAI and Analytics domains, Deepthi works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.
 Nishanth Mudkey is a Specialist Solutions Architect for Data, AI/ML at Amazon Web Services. He focuses on helping customers design and implement innovative solutions using AWS’s AI/ML services, including Amazon Bedrock and Amazon SageMaker. With expertise spanning big data, deep learning, and generative AI, Nishanth brings both technical depth and practical experience to cloud architecture.
Nishanth Mudkey is a Specialist Solutions Architect for Data, AI/ML at Amazon Web Services. He focuses on helping customers design and implement innovative solutions using AWS’s AI/ML services, including Amazon Bedrock and Amazon SageMaker. With expertise spanning big data, deep learning, and generative AI, Nishanth brings both technical depth and practical experience to cloud architecture.
 Pijush Chatterjee is a GenAI/ML Specialist at AWS based in New York. He has 25+ years of experience in data, analytics and ML. He specializes in business transformation leveraging Generative AI and Cloud.
Pijush Chatterjee is a GenAI/ML Specialist at AWS based in New York. He has 25+ years of experience in data, analytics and ML. He specializes in business transformation leveraging Generative AI and Cloud.
 Michelle Tat is a Senior Data Scientist at Care Access focused on using Machine Learning to help optimize clinical trials implementation outcomes.
Michelle Tat is a Senior Data Scientist at Care Access focused on using Machine Learning to help optimize clinical trials implementation outcomes.
 Christopher Penrose is a Staff Data Engineer at Care Access focused on building sustainable ModelOps and LLMOps systems.
Christopher Penrose is a Staff Data Engineer at Care Access focused on building sustainable ModelOps and LLMOps systems.
 Rasmus Buchmann is a Senior Staff Data Engineer at Care Access focused on developing and architecting scalable, enterprise-grade machine learning applications.
Rasmus Buchmann is a Senior Staff Data Engineer at Care Access focused on developing and architecting scalable, enterprise-grade machine learning applications.
 Daniel Hansen is a Senior Data Engineer at Care Access focused on machine learning and generative AI solutions engineering and architecture.
Daniel Hansen is a Senior Data Engineer at Care Access focused on machine learning and generative AI solutions engineering and architecture.



