


Time series forecasting helps businesses predict future trends based on historical data patterns, whether it’s for sales projections, inventory management, or demand forecasting. Traditional approaches require extensive knowledge of statistical methods and data science methods to process raw time series data.
Amazon SageMaker Canvas offers no-code solutions that simplify data wrangling, making time series forecasting accessible to all users regardless of their technical background. In this post, we explore how SageMaker Canvas and SageMaker Data Wrangler provide no-code data preparation techniques that empower users of all backgrounds to prepare data and build time series forecasting models in a single interface with confidence.
Solution overview
Using SageMaker Data Wrangler for data preparation allows for the modification of data for predictive analytics without programming knowledge. In this solution, we demonstrate the steps associated with this process. The solution includes the following:
- Data Import from varying sources
- Automated no-code algorithmic recommendations for data preparation
- Step-by-step processes for preparation and analysis
- Visual interfaces for data visualization and analysis
- Export capabilities post data preparation
- Built in security and compliance features
In this post, we focus on data preparation for time series forecasting using SageMaker Canvas.
Walkthrough
The following is a walkthrough of the solution for data preparation using Amazon SageMaker Canvas. For the walkthrough, you use the consumer electronics synthetic dataset found in this SageMaker Canvas Immersion Day lab, which we encourage you to try. This consumer electronics related time series (RTS) dataset primarily contains historical price data that corresponds to sales transactions over time. This dataset is designed to complement target time series (TTS) data to improve prediction accuracy in forecasting models, particularly for consumer electronics sales, where price changes can significantly impact buying behavior. The dataset can be used for demand forecasting, price optimization, and market analysis in the consumer electronics sector.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Solution walkthrough
Below, we will provide the solution walkthrough and explain how users are able to use a dataset, prepare the data using no code using Data Wrangler, and run and train a time series forecasting model using SageMaker Canvas.
Sign in to the AWS Management Console and go to Amazon SageMaker AI and then to Canvas. On the Get started page, select Import and prepare option. You will see the following options to import your data set into Sagemaker Data Wrangler. First, select Tabular Data as we will be utilizing this data for our time series forecasting. You will see the following options available to select from:
- Local upload
- Canvas Datasets
- Amazon S3
- Amazon Redshift
- Amazon Athena
- Databricks
- MySQL
- PostgreSQL
- SQL Server
- RDS

For this demo, select Local upload. When you use this option, the data is stored in the SageMaker instance, specifically on an Amazon Elastic File System (Amazon EFS) storage volume in the SageMaker Studio environment. This storage is tied to the SageMaker Studio instance, but for more permanent data storage purposes, Amazon Simple Storage Service (Amazon S3) is a good option when working with SageMaker Data Wrangler. For long term data management, Amazon S3 is recommended.

Select the consumer_electronics.csv file from the prerequisites. After selecting the file to import, you can use the Import settings panel to set your desired configurations. For the purpose of this demo, leave the options to their default values.

After the import is complete, use the Data flow options to modify the newly imported data. For future data forecasting, you may need to clean up data for the service to properly understand the values and disregard any errors in the data. SageMaker Canvas has various offerings to accomplish this. Options include Chat for data prep with natural language data modifications and Add Transform. Chat for data prep may be best for users who prefer natural language processing (NLP) interactions and may not be familiar with technical data transformations. Add transform is best for data professionals who know which transformations they want to apply to their data.
For time series forecasting using Amazon SageMaker Canvas, data must be prepared in a certain way for the service to properly forecast and understand the data. To make a time series forecast using SageMaker Canvas, the documentation linked mentions the following requirements:
- A timestamp column with all values having the datetime type.
- A target column that has the values that you’re using to forecast future values.
- An item ID column that contains unique identifiers for each item in your dataset, such as SKU numbers.
The datetime values in the timestamp column must use one of the following formats:
- YYYY-MM-DD HH:MM:SS
- YYYY-MM-DDTHH:MM:SSZ
- YYYY-MM-DD
- MM/DD/YY
- MM/DD/YY HH:MM
- MM/DD/YYYY
- YYYY/MM/DD HH:MM:SS
- YYYY/MM/DD
- DD/MM/YYYY
- DD/MM/YY
- DD-MM-YY
- DD-MM-YYYY
You can make forecasts for the following intervals:
- 1 min
- 5 min
- 15 min
- 30 min
- 1 hour
- 1 day
- 1 week
- 1 month
- 1 year
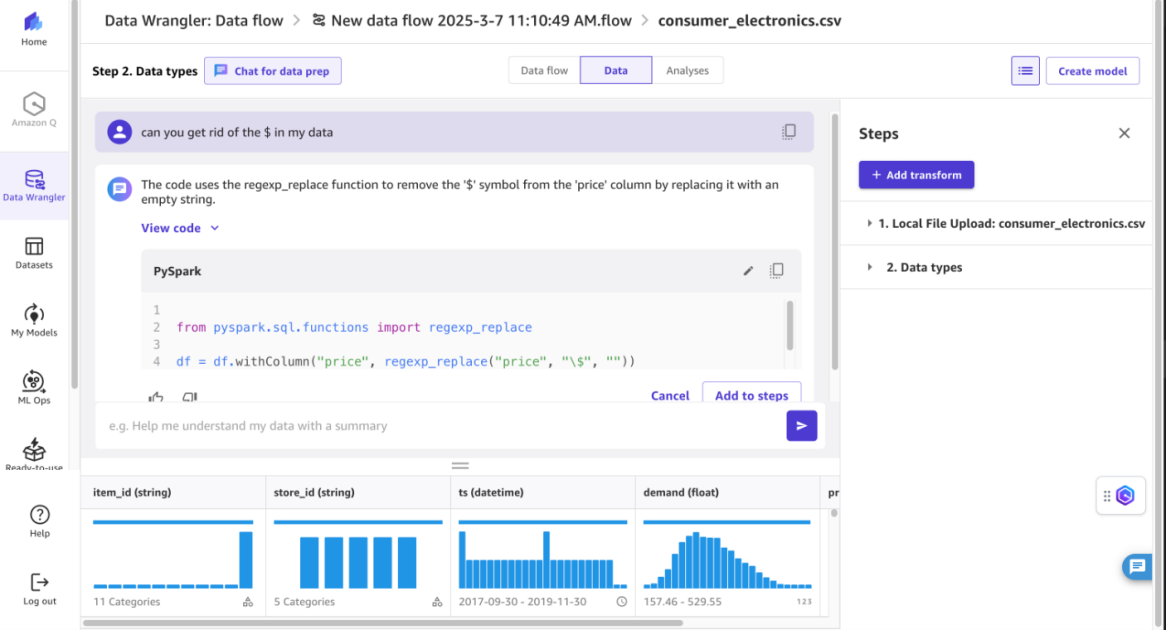
For this example, remove the $ in the data, by using the Chat for data prep option. Give the chat a prompt such as Can you get rid of the $ in my data, and it will generate code to accommodate your request and modify the data, giving you a no-code solution to prepare the data for future modeling and predictive analysis. Choose Add to Steps to accept this code and apply changes to the data.

You can also convert values to float data type and check for missing data in your uploaded CSV file using either Chat for data prep or Add Transform options. To drop missing values using Data Transform:
- Select Add Transform from the interface
- Choose Handle Missing from the transform options
- Select Drop missing from the available operations
- Choose the columns you want to check for missing values
- Select Preview to verify the changes
- Choose Add to confirm and apply the transformation

For time-series forecasting, inferring missing values and resampling the data set to a certain frequency (hourly, daily, or weekly) are also important. In SageMaker Data Wrangler, the frequency of data can be altered by choosing Add Transform, selecting Time Series, selecting Resample from the Transform drop down, and then selecting the Timestamp dropdown, ts in this example. Then, you can select advanced options. For example, choose Frequency unit and then select the desired frequency from the list.

SageMaker Data Wrangler offers several methods to handle missing values in time-series data through its Handle missing transform. You can choose from options such as forward fill or backward fill, which are particularly useful for maintaining the temporal structure of the data. These operations can be applied by using natural language commands in Chat for data prep, allowing flexible and efficient handling of missing values in time-series forecasting preparation.
To create the data flow, choose Create model. Then, choose Run Validation, which checks the data to make sure the processes were done correctly. After this step of data transformation, you can access additional options by selecting the purple plus sign. The options include Get data insights, Chat for data prep, Combine data, Create model, and Export.
The prepared data can then be connected to SageMaker AI for time series forecasting strategies, in this case, to predict the future demand based on the historical data that has been prepared for machine learning.
When using SageMaker, it is also important to consider data storage and security. For the local import feature, data is stored on Amazon EFS volumes and encrypted by default. For more permanent storage, Amazon S3 is recommended. S3 offers security features such as server-side encryption (SSE-S3, SSE-KMS, or SSE-C), fine-grained access controls through AWS Identity and Access Management (IAM) roles and bucket policies, and the ability to use VPC endpoints for added network security. To help ensure data security in either case, it’s important to implement proper access controls, use encryption for data at rest and in transit, regularly audit access logs, and follow the principle of least privilege when assigning permissions.
In this next step, you learn how to train a model using SageMaker Canvas. Based on the previous step, select the purple plus sign and select Create Model, and then select Export to create a model. After selecting a column to predict (select price for this example), you go to the Build screen, with options such as Quick build and Standard build. Based on the column chosen, the model will predict future values based on the data that is being used.

Clean up
To avoid incurring future charges, delete the SageMaker Data Wrangler data flow and S3 Buckets if used for storage.
- In the SageMaker console, navigate to Canvas
- Select Import and prepare
- Find your data flow in the list
- Click the three dots (⋮) menu next to your flow
- Select Delete to remove the data flow

If you used S3 for storage:
- Open the Amazon S3 console
- Navigate to your bucket
- Select the bucket used for this project
- Choose Delete
- Type the bucket name to confirm deletion
- Select Delete bucket
Conclusion
In this post, we showed you how Amazon SageMaker Data Wrangler offers a no-code solution for time series data preparation, traditionally a task requiring technical expertise. By using the intuitive interface of the Data Wrangler console and natural language-powered tools, even users who don’t have a technical background can effectively prepare their data for future forecasting needs. This democratization of data preparation not only saves time and resources but also empowers a wider range of professionals to engage in data-driven decision-making.
About the author
 Muni T. Bondu is a Solutions Architect at Amazon Web Services (AWS), based in Austin, Texas. She holds a Bachelor of Science in Computer Science, with concentrations in Artificial Intelligence and Human-Computer Interaction, from the Georgia Institute of Technology.
Muni T. Bondu is a Solutions Architect at Amazon Web Services (AWS), based in Austin, Texas. She holds a Bachelor of Science in Computer Science, with concentrations in Artificial Intelligence and Human-Computer Interaction, from the Georgia Institute of Technology.



