


In this post, we demonstrate how to build a multi-agent system using multi-agent collaboration in Amazon Bedrock Agents to solve complex business questions in the biopharmaceutical industry. We show how specialized agents in research and development (R&D), legal, and finance domains can work together to provide comprehensive business insights by analyzing data from multiple sources.
Amazon Bedrock Agents and multi-agent collaboration
Business intelligence and market research enable large and small businesses to capture the trends of the industry, competitive landscape through data, and influences key business strategies. For example, biopharmaceutical companies use data to understand drug market size, clinical trials, prevalence of side effects, and innovation and pitfalls through analyzing patent and legal briefs to form investment strategies. In doing so, organizations face the challenges of accessing and analyzing information scattered across multiple data sources. Consolidating and querying these disparate datasets can be a complex and time-consuming task, requiring developers to navigate different data formats, query languages, and access mechanisms. Additionally, gaining a comprehensive understanding of an organization’s operations often requires combining data insights from various segments, such as legal, finance, and R&D.
Generative AI agentic systems have emerged as a promising solution, enabling organizations to use generative AI for autonomous reasoning and action-based tasks. However, many agentic systems to-date are built with a single-agent setup, which poses challenges in a complex business environment. Besides the challenge of managing multiple data sources, encoding information and guidance for multiple business domains might cause the prompt for an agent’s large language model (LLM) to grow to such an extent that is suffers from “forgetting the middle” of a long context. Therefore, there is a trade-off between the breadth vs. depth of knowledge for each domain that can be encoded in an agent effectively. Additionally, the use of a single LLM with an agent limits cost, latency, and accuracy optimizations for the selected model.
Amazon Bedrock Agents and its multi-agent collaboration feature provides powerful, enterprise-ready solutions for addressing these challenges and building intelligent and automated agentic systems. As a managed service within the AWS ecosystem, Amazon Bedrock Agents offers seamless integration with AWS data sources, built-in security controls, and enterprise-grade scalability. It contains built-in support for additional Amazon Bedrock features such as Amazon Bedrock Guardrails and Amazon Bedrock Knowledge Bases. The service significantly reduces deployment overhead, empowering developers to focus on agent logic through an API-driven, familiar AWS Cloud environment and console. The supervisor agent model with specialized sub-agents enables efficient distributed problem-solving, breaking down complex tasks with intelligent routing.
In this post, we discuss how to build a multi-agent system using multi-agent collaboration to solve complex business questions faced in a fictional biopharmaceutical company that requires expertise and data from three specialized domains: R&D, legal, and finance. We demonstrate how data in disparate sources can be combined intelligently to support complex reasoning, and how agent collaboration facilitates open-ended question answering, such as “What are the potential legal and financial risks associated with the side effects of therapeutic product X, and how might they affect the company’s long-term stock performance?”
(Below image depicts the roles of supervisor agent and the 3 subagents being used in our pharmaceutical example along with the benefits of using Multi Agent Collaboration. )

Solution overview
Our use case centers around PharmaCorp, a fictional pharmaceutical company, which faces the challenge of managing vast amounts of data across its Pharma R&D, Legal, and Finance divisions. Each division works with structured data, such as stock prices, and unstructured data, such as clinical trial reports. The data for each division is located in different data stores, which makes it difficult for teams to access cross-functional insights and slows down decision-making processes.
To address this, we build a multi-agent system with domain-specific sub-agents for each division using multi-agent collaboration within Amazon Bedrock Agents. These sub-agents efficiently handle data queries and information retrieval, and the main agent passes necessary context between sub-agents and synthesizes insights across divisions. The multi-agent setup empowers PharmaCorp to access expertise and information within minutes that would otherwise take hours of human effort to compile. This approach breaks down data silos and strengthens organizational collaboration.
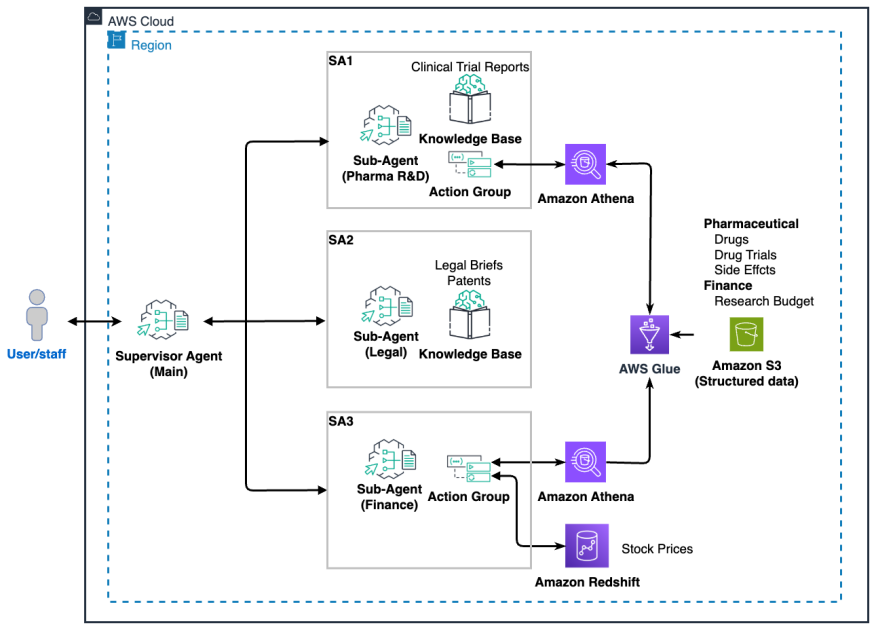
The following architecture diagram illustrates the solution setup.

The main agent acts as an orchestrator, asking questions to multiple sub-agents and synthesizing retrieved data:
- The R&D sub-agent has access to clinical trial data through Amazon Athena and unstructured clinical trial reports
- The legal sub-agent has access to unstructured patents and lawsuit legal briefs
- The finance sub-agent has access to research budget data through Athena and historical stock price data stored in Amazon Redshift
Each sub-agent has granular permissions to only access the data in its domain. Detailed information about the data and models used and main agent interactions are described in the following sections.
Dataset
We generated synthetic data using Anthropic’s Claude 3.5 Sonnet model, comprised of three domains: Pharma R&D, Legal, and Finance. The domains contain structured data stored in SQL tables and unstructured data that is used in domain knowledge bases. The data can be accessed through the following files: R&D, Legal, Finance.
Efforts have been made to align synthetic data within and across domains. For example, clinical trial reports map to each trial and side effects in related tables. Rises and dips in stock prices tend to correlate with patents and lawsuits. However, there might still be minor inconsistencies between data.
Pharma R&D domain
The Pharma R&D domain has three tables: Drugs, Drug Trials, and Side Effects. Each table is queried from Amazon Simple Storage Service (Amazon S3) through Athena. The Drugs table contains information on the company’s available products, therapeutic areas, target conditions, mechanisms of action, development phase, discovery year, and lead scientist. The Drug Trials table contains information on specific trials for each drug such as phase, dates, number of participations, and outcomes. The Side Effects table contains side effects, frequency, and severity reported from each trial.
The unstructured data for the Pharma R&D domain consists of synthetic clinical trial reports for each trial, which contain more detailed information about the trial design, outcomes, and recommendations.
Legal domain
The Legal domain has unstructured data consisting of patents and lawsuit legal briefs. The patents contain information about invention background, description, and experimental results. The legal briefs contain information about lawsuit court proceedings, outcomes, and analysis.
Finance domain
The Finance domain has two tables: Stock Price and Research Budgets. The Stock Price table is stored in Amazon Redshift and contains PharmaCorp’s historical monthly stock prices and volume. Amazon Redshift is a database optimized for online analytical processing (OLAP), which generally entails analyzing large amounts of data and performing complex analysis, as might be done by analysts looking at historical stock prices. The Research Budgets table is accessed from Amazon S3 through Athena and contains annual budgets for each department.
The data setup showcases how a multi-agent framework can synthesize data from multiple data sources and databases. In practice, data could also be stored in other databases such as Amazon Relational Database Service (Amazon RDS).
Models used
Anthropic’s Claude 3 Sonnet, which has a good balance of intelligence and speed, is used in this multi-agent demonstration. With the multi-agent setup, you can also employ a more intelligent or a smaller, faster model depending on the use case and requirements such as accuracy and latency.
Prerequisites
To deploy this solution, you need the following prerequisites:
Deploy the solution
To deploy the solution resources, we use AWS CloudFormation. The CloudFormation template creates two S3 buckets, two AWS Lambda functions, an Amazon Bedrock agent, an Amazon Bedrock knowledge base, and an Amazon Elastic Compute Cloud (Amazon EC2) instance.
Download the provided CloudFormation template, then complete the following steps to deploy the stack:
- Open the AWS CloudFormation console (the preferred AWS Regions are
us-west-2orus-east-1for the solution). - Choose Stacks in the navigation pane.
- Choose Create stack and With new resources (standard).
- Select Choose existing template and upload the provided CloudFormation template file.
- Enter a stack name, then choose Next.
- Leave the stack settings as default and choose Next.
- Select the acknowledgement check box and create the stack.
After the stack is complete, you can view the new supervisor agent on the Amazon Bedrock console.
An example of agent collaboration
After you deploy the solution, you can test the communication among agents that help answer complex questions across PharmaCorp’s three divisions. For example, we ask the main agent “How did the results of NeuroClear’s Phase 2 trials affect PharmaCorp’s stock price, patent filings, and potential legal risks?”
This question requires a comprehensive understanding of the relationships between NeuroClear’s clinical trial results, financial impacts, and legal outcomes for PharmaCorp. Let’s see how the multi-agent system addresses this complex query.
The main agent identifies that it needs input from three specialized sub-agents to fully assess how NeuroClear’s clinical trial results might impact PharmaCorp’s legal and financial performance. It breaks down the user’s question into key components and develops a plan to gather detailed insights from each expert. The following is its chain-of-thought reasoning, task breakdown, and sub-agent routing:
Then, the main agent asks a question to the R&D sub-agent:
The R&D sub-agent correctly plans and executes its own sequence of steps, which include performing queries and searching its own knowledge base. It responds with the following:
The main agent takes this information and determines its next step:
It asks the finance sub-agent the following:
Through this example, we can see how multi-agent collaboration enables a comprehensive analysis of complex business questions by using specialized knowledge from different domains. The main agent effectively orchestrates the interaction between sub-agents, synthesizing their insights to provide a holistic answer that considers R&D, financial, and legal aspects of the NeuroClear clinical trials and their potential impacts on PharmaCorp.
Clean up
When you’re done testing the agent, complete the following steps to clean up your AWS environment and avoid unnecessary charges:
- Delete the S3 buckets:
- On the Amazon S3 console, empty the buckets
structured-data-${AWS::AccountId}-${AWS::Region}andunstructured-data-${AWS::AccountId}-${AWS::Region}. Make sure that both of these buckets are empty by deleting the files. - Select each file, choose Delete, and confirm by entering the bucket name.
- On the Amazon S3 console, empty the buckets
- Delete the Lambda functions:
- On the Lambda console, select the
CopyDataLambdafunction. - Choose Delete and confirm the action.
- Repeat these steps for the
CopyUnstructuredDataLambdafunction.
- On the Lambda console, select the
- Delete the Amazon Bedrock agent:
- On the Amazon Bedrock console, choose Agents in the navigation pane.
- Select the agent, then choose Delete.
- Delete the Amazon Bedrock knowledge base in Bedrock:
- On the Amazon Bedrock console, choose Knowledge bases under Builder tools in the navigation pane.
- Select the knowledge base and choose Delete.
- Delete the EC2 instance:
- On the Amazon EC2 console, choose Instances in the navigation pane.
- Select the EC2 instance you created, then choose Delete.
Business impact
Implementing this multi-agent system using Amazon Bedrock Agents can provide significant benefits for pharmaceutical companies. By automating data retrieval and analysis across domains, companies can reduce research time and enable faster, data-driven decision-making, especially when domain experts are distributed across different organizational units with limited direct interaction. The system’s ability to provide comprehensive, cross-functional insights in minutes can lead to improved risk mitigation, because potential legal and financial issues can be identified earlier by connecting disparate data points. This automation also allows for more effective allocation of human resources, freeing up experts to focus on high-value tasks rather than routine data analysis.
Our example demonstrates the power of multi-agent systems in pharmaceutical research and development, but the applications of this technology extend far beyond a single use case. For example, biotech companies can accelerate the discovery of cancer biomarkers by having specialist agents extract genomic signals from Amazon Redshift, perform Kaplan-Meier survival analyses, and interpret CT scans in parallel. Large health systems could automatically aggregate patient records, lab results, and trial data to streamline care coordination and flag urgent cases. Travel agencies can orchestrate end‑to‑end itineraries, and firms can manage personalized client communications. For more information on potential applications, see the following posts:
Although the potential of multi-agent systems is compelling across these diverse applications, it’s important to understand the practical considerations in implementing such systems. Complex orchestration workflows can drive up inference costs through multiple model calls, increase end‑to‑end latency, amplify testing and maintenance requirements, and introduce operational overhead around rate limits, retries, and inter‑agent or data connection protocols. However, the state of the art is rapidly advancing. New generations of faster, cheaper models can help keep per‑call expenses and latency low, and more powerful models can accomplish tasks in fewer turns. Observability tools offer end‑to‑end tracing and dashboarding for multi‑agent pipelines. Finally, protocols like Anthropic’s Model Context Protocol are beginning to standardize the way agents access data, paving the way for robust multi‑agent ecosystems.
Conclusion
In this post, we explored how a multi-agent generative AI system, implemented with Amazon Bedrock Agents using multi-agent collaboration, addresses data access and analysis challenges across multiple business domains. Through a demo use case with a fictional pharmaceutical company managing data across its different divisions, we showcased how specialized sub-agents tailored to each domain streamline information retrieval and synthesis. Each sub-agent uses domain-optimized models and securely accesses relevant data sources, enabling the organization to generate cross-functional insights.
With this multi-agent architecture, organizations can overcome data silos, enhance collaboration, and achieve efficient, data-driven decision-making while optimizing for cost, latency, and security. Amazon Bedrock Agents with multi-agent collaboration facilitates this setup by providing a secure, scalable framework that manages the collaboration, communication, and task delegation between agents. Explore other demos and workshops about multi-agent collaboration in Amazon Bedrock in the following resources:
About the authors
 Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.
Justin Ossai is a GenAI Labs Specialist Solutions Architect based in Dallas, TX. He is a highly passionate IT professional with over 15 years of technology experience. He has designed and implemented solutions with on-premises and cloud-based infrastructure for small and enterprise companies.
 Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
Michael Hsieh is a Principal AI/ML Specialist Solutions Architect. He works with HCLS customers to advance their ML journey with AWS technologies and his expertise in medical imaging. As a Seattle transplant, he loves exploring the great mother nature the city has to offer, such as the hiking trails, scenery kayaking in the SLU, and the sunset at Shilshole Bay.
 Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
Shreya Mohanty is a Deep Learning Architect at the AWS Generative AI Innovation Center, where she partners with customers across industries to design and implement high-impact GenAI-powered solutions. She specializes in translating customer goals into tangible outcomes that drive measurable impact.
 Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.
Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.



