



Artificial intelligence (AI) reasoning capabilities determine whether models can handle complex, real-world tasks beyond simple pattern matching. With strong reasoning, models can identify problems from ambiguous descriptions, apply policies under competing constraints, adapt tone to sensitive situations, and provide complete solutions that address root causes. Without robust reasoning, AI systems fail when faced with nuanced scenarios requiring judgment, context awareness, and multi-step problem-solving.
This post evaluates the reasoning capabilities of our latest offering in the Nova family, Amazon Nova Lite 2.0, using practical scenarios that test these critical dimensions. We compare its performance against other models in the Nova family—Lite 1.0, Micro, Pro 1.0, and Premier—to elucidate how the latest version advances reasoning quality and consistency.
Solution overview
We evaluate five Amazon Nova models across five customer support scenarios, measuring performance on eight dimensions:
- Problem identification
- Solution completeness
- Policy adherence
- Factual accuracy
- Empathy and tone
- Communication clarity
- Logical coherence
- Practical utility
An independent evaluator model (gpt-oss-20b) provides automated, unbiased scoring.
The evaluation architecture uses the same Region: us-east-1 and automatically handles different API formats: Converse API for Nova, OpenAI Chat Completions for gpt-oss-20b.
The sample notebook is available in the GitHub repository.
Test scenarios
To generate the scenarios evaluation dataset, we use Claude Sonnet 4.5 by Anthropic on Amazon Bedrock to generate a sample of 100 scenarios that pertain to common customer support interactions. We don’t use any of the Nova models to generate the scenarios to avoid any bias. We then randomly select five scenarios for our testing purposes that evaluate common real-world reasoning challenges:
- Angry customer complaint – Tests de-escalation, empathy, and problem resolution when a customer threatens to leave after delayed delivery and poor service.
- Software technical problem – Evaluates technical troubleshooting when an app crashes during photo uploads despite basic troubleshooting attempts.
- Billing dispute – Assesses investigation skills and security awareness for unrecognized charges potentially indicating unauthorized access.
- Product defect report – Measures warranty policy application and customer service for a two-month-old defective product.
- Account security concern – Tests urgency response and security protocols for unauthorized password changes and fraudulent purchases.
Each scenario includes key issues to identify, required solutions, and relevant policies—providing objective criteria for evaluation. Depending on your industry/domain/use case, the scenarios and associated context may be different.
Implementation details
The evaluation framework establishes a comprehensive methodology for assessing model performance across multiple dimensions simultaneously. This systematic approach ensures that each model undergoes identical testing conditions, enabling fair comparison of reasoning capabilities across the Nova family. The technical implementation handles the complexity of managing different API formats while maintaining evaluation consistency. The framework assumes an active AWS account, access to Nova models and gpt-oss-20b, along with the availability of the boto3 SDK, and pandas, matplotlib, seaborn, scipy and numpy packages.
Model invocation
The system automatically detects which API format each model requires and routes requests accordingly. Nova models (Lite, Micro, Pro, Premier) use Amazon Bedrock Converse API, which provides a unified interface for conversational interactions. gpt-oss models use the OpenAI Chat Completions format, requiring a different request structure with the InvokeModel API. The invocation function checks the model identifier to determine the appropriate format. For gpt-oss models, it constructs a JSON request body with messages, token limits, and temperature settings, then parses the response to extract the generated content. For Nova models, it uses the Converse API with structured message objects and inference configuration parameters, extracting the response from the output message content. This dual-API approach supports seamless evaluation across different model families without requiring separate code paths or manual configuration changes. The same evaluation logic works for all models regardless of their underlying API requirements, with the system handling format differences transparently. The architecture also allows us to use models from different Regions while maintaining a single evaluation workflow.
The evaluation framework uses optimized prompts generated by the Amazon Bedrock Prompt Optimizer API. The optimizer analyzes and rewrites raw prompts to improve model performance with better structure, clarity, and organization, creating model-specific optimizations for each Nova model.
A scenario with the optimized prompt is shown in the following example:
Evaluation Framework
The evaluator receives the scenario, model response, and evaluation criteria. We employ a two-step scoring process: first, the evaluator assigns a category label that best characterizes the response; then, the evaluator assigns a predetermined score corresponding to that category label. This approach ensures a consistent and uniform scoring methodology across all model responses.
The evaluation prompt structure:
The evaluator must justify scores, providing transparency into the assessment. To address transparency concerns in AI evaluation, the evaluator provides detailed reasoning for each of the eight dimensions, plus an overall justification. This ensures that scores are not just numerical but backed by specific explanations of why each score was assigned.
Large language model (LLM)-as-a-judge evaluation
Machine translation-based evaluation techniques like ROUGE and BLEU fall short when it comes to open ended conversations. LLM-as-a-judge provides scalability, flexibility and evaluations that closely match human preferences up to 80%.
Refer to the comparison table in the README for further details.
Evaluation process
For each model and scenario combination, we perform 10 runs to measure consistency. This produces 250 evaluations (5 models × 5 scenarios × 10 runs) providing a statistical spread through multiple measurements. The number of runs and scenarios can be increased according to the specific use case. The framework includes diagnostic checks to verify evaluation quality and reliability. Failed evaluations (where the evaluator returns a score of 0 due to technical issues such as JSON parsing errors, or when models don’t respond owing to blocked responses adhering to Responsible AI criteria) are excluded from mean and standard deviation calculations to ensure accurate performance metrics. This prevents technical failures from artificially lowering model scores.
Results
The chosen scenarios and approach described here enable deep statistical analysis of model performance patterns. By examining both individual scenario outcomes and aggregate metrics, we can identify strengths and potential areas for improvement across the Nova model family. This multi-dimensional analysis approach provides confidence in the reliability of performance rankings.
Statistical analysis
The statistical evaluation we use follow the methods outlined in Miller, 2024. To quantify uncertainty in model performance estimates, we calculate standard error (SE) as:
SE = √(σ^2/n),
where σ^2 is the sample variance, and n is the sample size. SE measures how precise our estimate of the mean is and tells us how much the sample mean would vary if we repeated the evaluation many times. The standard error allows us to construct 95% confidence intervals (CI = μ± 1.96×SE), where μ is the sample mean. This provides plausible ranges for true model performance, facilitating statistical significance testing through interval overlap analysis. In addition, we introduce a coefficient of variation (CV) based consistency score calculated as (100 – CV%), where CV% = (σ/μ)×100, and σ is the standard deviation. This normalizes reliability measurement on a 0-100 scale, thereby providing an intuitive metric for response stability. Finally, zero-exclusion averaging prevents failed evaluations from artificially deflating scores, while error bars on visualizations transparently communicate uncertainty. For the sake of completeness, the code in the GitHub repository calculates other statistics such as a minimum detectable effect that demonstrates the ability to reliably detect meaningful performance differences, a pairwise model comparison metric that identifies correlations between model responses, and a power analysis that validates the chosen sample size. These methodologies transform the evaluation from simple score comparison into rigorous experimental science with quantified uncertainty, enabling confident conclusions about model performance differences.
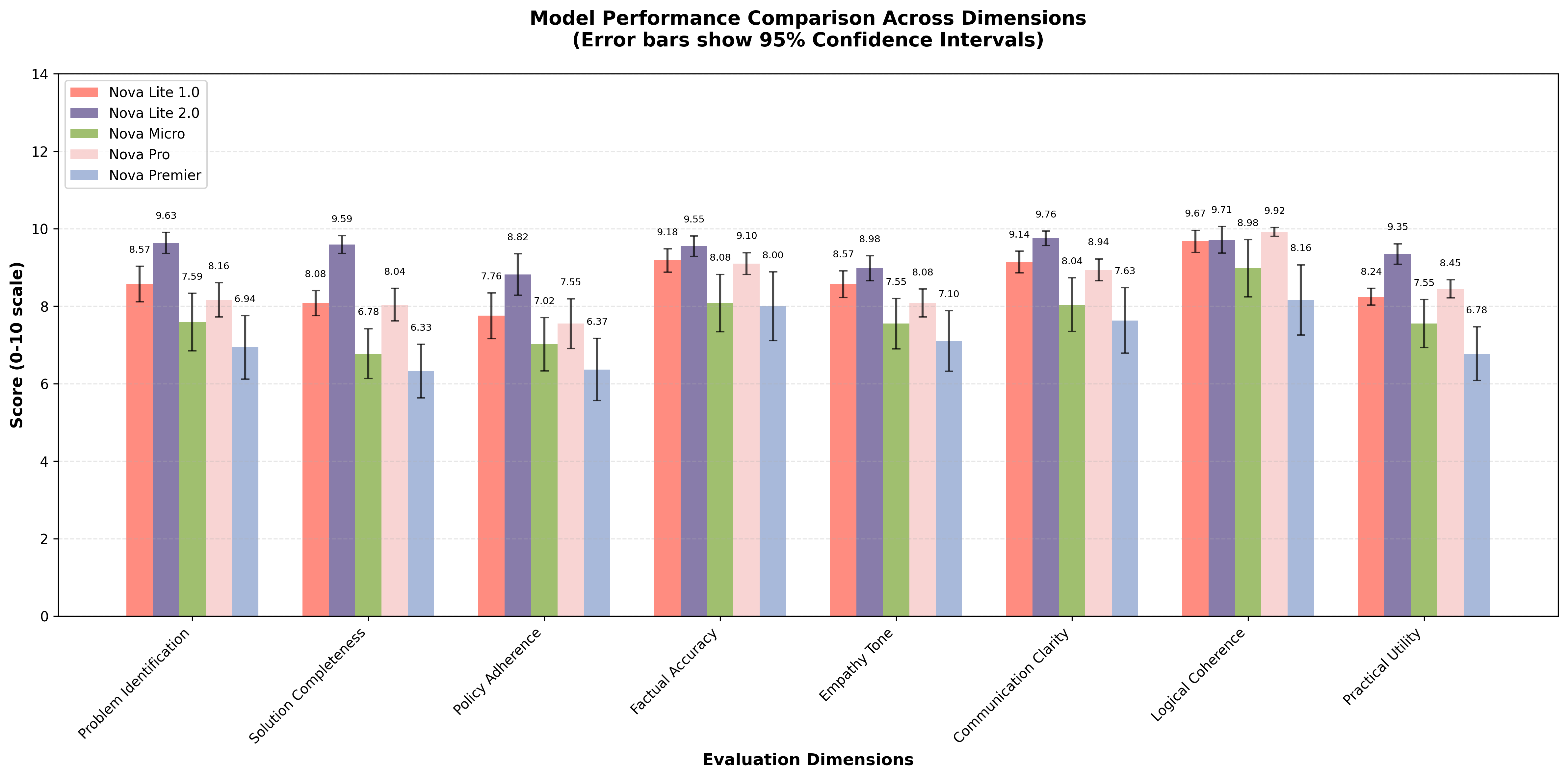
Figure 1 Performance of models across the dimensions considered in the study with 95% confidence intervals
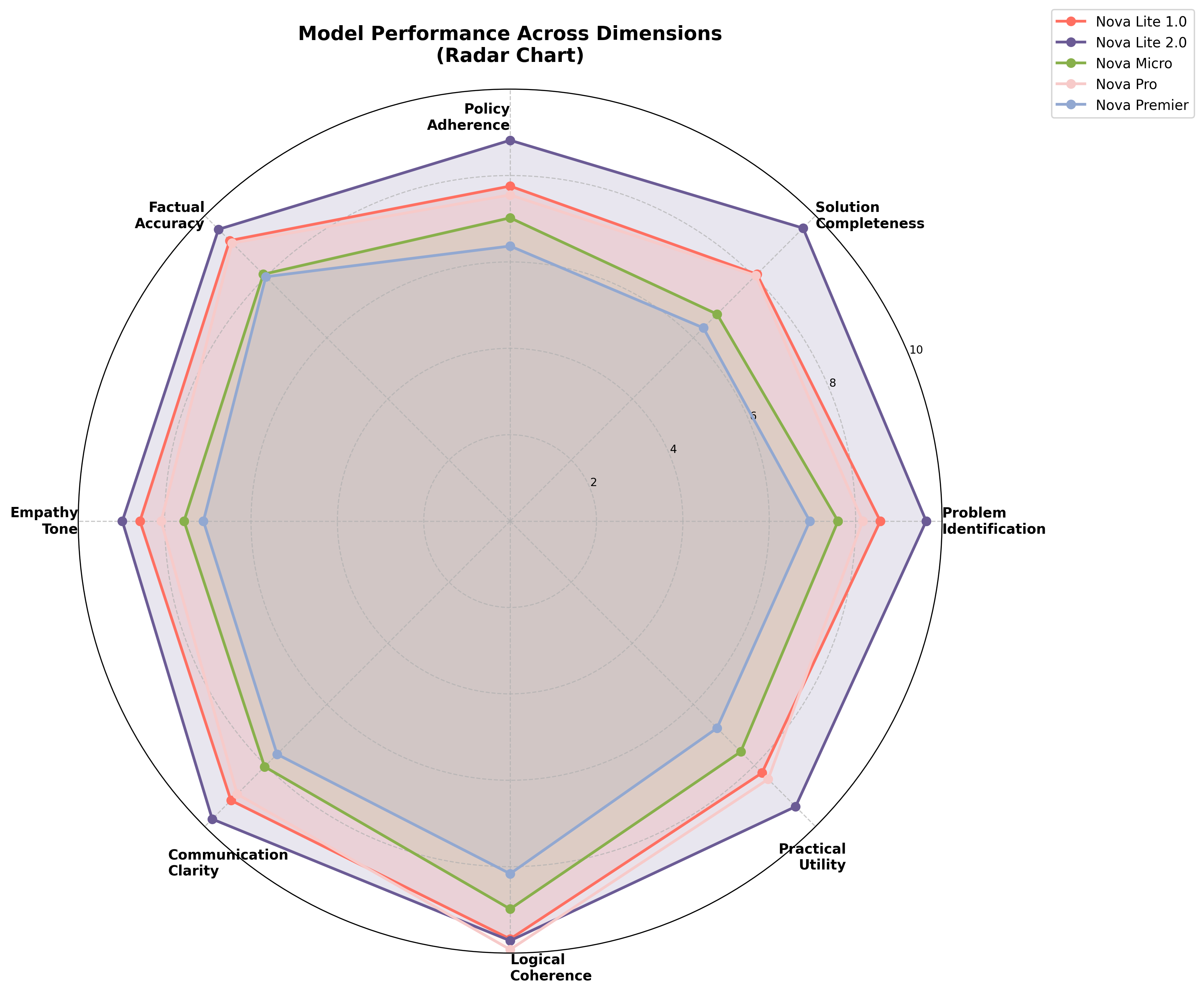
Figure 2 Overall performance of Nova Lite 2.0 compared to other models in the Nova family
Figure 1 shows the performance of models with scores averaged across all the runs for each dimension considered in the study; this is also depicted on the radar chart in Figure 2. Table 1 shows the scores across all dimensions considered in the study. Nova Lite 2.0 achieved the highest overall score (9.42/10) with a standard error of 0.08 and a coefficient of variation of 5.55%, demonstrating high-quality reasoning.
| Metric | Nova Lite 2.0 | Nova Lite 1.0 | Nova Pro 1.0 | Nova Micro | Nova Premier |
| Overall Score | 9.42 | 8.65 | 8.53 | 7.70 | 7.16 |
| Standard Error (SE) | 0.08 | 0.09 | 0.12 | 0.32 | 0.38 |
| 95% Confidence Interval | [9.28, 9.57] | [8.48, 8.82] | [8.30, 8.76] | [7.08, 8.32] | [6.41, 7.91] |
| Consistency Score (CV-based) | 94.45 | 93.05 | 90.46 | 71.37 | 62.96 |
| Coefficient of Variation | 5.55% | 6.95% | 9.54% | 28.63% | 37.04% |
Table 1: Overall Model Performance Summary
| Metric | Nova Lite 2.0 | Nova Lite 1.0 | Nova Pro 1.0 | Nova Micro | Nova Premier |
| Problem Identification | 9.63 ± 0.27 | 8.57 ± 0.46 | 8.16 ± 0.44 | 7.59 ± 0.74 | 6.94 ± 0.82 |
| Solution Completeness | 9.59 ± 0.23 | 8.08 ± 0.32 | 8.04 ± 0.42 | 6.78 ± 0.65 | 6.33 ± 0.69 |
| Policy Adherence | 8.82 ± 0.54 | 7.76 ± 0.59 | 7.55 ± 0.64 | 7.02 ± 0.69 | 6.37 ± 0.81 |
| Factual Accuracy | 9.55 ± 0.26 | 9.18 ± 0.30 | 9.10 ± 0.28 | 8.08 ± 0.74 | 8.00 ± 0.89 |
| Empathy Tone | 8.98 ± 0.33 | 8.57 ± 0.34 | 8.08 ± 0.36 | 7.55 ± 0.65 | 7.10 ± 0.79 |
| Communication Clarity | 9.76 ± 0.19 | 9.14 ± 0.28 | 8.94 ± 0.28 | 8.04 ± 0.69 | 7.63 ± 0.85 |
| Logical Coherence | 9.71 ± 0.35 | 9.67 ± 0.29 | 9.92 ± 0.11 | 8.98 ± 0.74 | 8.16 ± 0.91 |
| Practical Utility | 9.35 ± 0.27 | 8.24 ± 0.22 | 8.45 ± 0.24 | 7.55 ± 0.62 | 6.78 ± 0.70 |
Table 2: Dimension-Level Performance of the Nova models (Mean Scores with 95% Confidence Intervals)
Table 2 shows the performance across the eight dimensions considered in the study. Nova Lite 2.0 achieved consistently high scores across all dimensions.
| Scenario | Nova Lite 2.0 | Nova Lite 1.0 | Nova Micro | Nova Pro 1.0 | Nova Premier |
| Account Security Concern | 9.25 | 7.95 | 7.65 | 6.90 | 2.00 |
| Angry Customer Complaint | 9.95 | 9.50 | 9.30 | 8.35 | 8.20 |
| Billing Dispute | 9.15 | 8.75 | 8.60 | 8.85 | 8.20 |
| Product Defect Report | 9.25 | 8.90 | 7.70 | 8.00 | 8.75 |
| Software Technical Problem | 10.00 | 8.20 | 8.55 | 8.75 | 8.60 |
Table 3 Summary of scores (on a scale of 1-10) across models and scenarios considered. A score of 2 for Nova Premier for Account Security Concern is due to Guardrails being invoked for almost all of the responses.
Table 3 summarizes the mean scores corresponding to each scenario considered in the study. Again, Nova Lite 2.0 achieves high scores across all dimensions.
Dimension analysis
The dimensional strengths of Nova Lite 2.0 demonstrate balanced capabilities across critical evaluation criteria. High scores in problem identification, communication, and logical reasoning indicate mature performance that translates effectively to real-world applications, distinguishing it from models that excel in individual dimensions but lack consistency.
Problem Identification: Nova Lite 2.0 excelled at identifying all key issues—crucial where missing problems lead to incomplete solutions.
Communication Clarity: The model achieved the highest score in this dimension, producing well-structured, actionable responses customers could follow easily.
Logical Coherence: Strong performance indicates the model maintains sound reasoning without contradictions across complex scenarios.
Empathy and Tone: High scores demonstrate appropriate emotional intelligence, critical for de-escalation and sensitive situations.
Table 4 shows sample evaluator explanations for high-scoring and low-scoring models, illustrating effective scoring methodology.
| Nova Lite 2.0 – Score: 10 – Category: “Excellent” The response explicitly recognizes the four key issues: it mentions the delayed delivery (“delay in receiving your laptop”), the poor customer service experience (“unhelpful interaction with our support team”), the customer’s loyalty (“a valued customer of five years”), and the refund request (“cancel your order and receive a full refund”). All issues are acknowledged with appropriate language. Nova Premier – Score: 6 – Category: “Adequate” |
Table 4 Sample explanations provided by the evaluator for Nova Lite 2.0 and Nova Premier for the Angry Customer scenario along the Problem Identification dimension
Key findings
The evaluation results reveal critical insights for model selection and deployment strategies. These findings emphasize considering multiple performance factors rather than focusing solely on aggregate scores, as optimal choices depend on specific application requirements and operational constraints.
- Multi-dimensional reasoning matters: Models scoring well on accuracy but poorly on empathy or clarity are unsuitable for customer-facing applications. The balanced performance of Nova Lite 2 across all dimensions makes it production-ready.
- Consistency predicts production success: The low variability of Nova Lite 2.0 versus other models indicates reliable performance across diverse scenarios—critical where inconsistent responses damage user trust.
- Real-world evaluation reveals practical capabilities: Synthetic benchmarks miss critical dimensions like empathy, policy adherence, and practical utility. This framework surfaces production-relevant capabilities.
Implementation considerations
Successfully implementing this evaluation framework requires attention to operational factors that significantly impact assessment quality and cost-effectiveness. The choice of evaluation methodology, scoring mechanisms, and technical infrastructure directly influences result reliability and scalability.
- Evaluator selection: We selected gpt-oss-20b to ensure independence from the Nova family, reducing potential bias. Amazon Bedrock offers built-in LLM-as-a-judge capabilities with standard metrics like correctness, completeness, and harmfulness. The framework presented in this post provides the flexibility to define specialized evaluation criteria and multi-dimensional assessments that can be customized to the specific use case of interest.
- Scenario design: Effective scenarios balance realism with measurability. Each includes specific details grounding evaluation in realistic contexts. Objective criteria—key issues to identify, required solutions, relevant policies—enable consistent scoring. Realistic complexity combining multiple problems (billing dispute + security breach) and competing priorities (urgency vs protocols) reveals how models handle real-world ambiguity and surfaces capability gaps.
- Statistical validation: Multiple runs per scenario provide confidence intervals and detect inconsistency, ensuring performance differences are statistically significant.
Key takeaways
Amazon Nova Lite 2.0 demonstrates impressive reasoning capabilities in tested real-world scenarios, achieving consistent high performance across diverse problem-solving tasks. Balanced scores across evaluation dimensions—from technical problem identification to empathetic communication—indicate robust reasoning potentially applicable to other domains after comprehensive testing. Multi-dimensional evaluation reveals nuanced model capabilities that single-metric benchmarks miss. Understanding performance across problem identification, solution completeness, policy adherence, empathy, clarity, and logical coherence provides actionable deployment insights. This practical testing methodology provides actionable insights for organizations evaluating AI systems. The framework’s focus on objective criteria, independent evaluation, and statistical validation creates reproducible assessments adaptable to domains requiring contextual judgment and problem-solving. As models advance, assessment methodologies must evolve to capture increasingly sophisticated reasoning capabilities—multi-turn conversations, complex decision-making under uncertainty, and nuanced judgment in ambiguous situations.
Conclusion
This comprehensive evaluation demonstrates that Amazon Nova Lite 2.0 delivers production-ready AI reasoning capabilities with measurable reliability across diverse business applications. The multi-dimensional assessment framework provides organizations with quantitative evidence needed to confidently deploy AI systems in critical operational environments.
Next steps
Evaluate Nova Lite 2.0 for your use case:
- Bedrock Model Evaluation: Start with model evaluation tools of Amazon Bedrock, including the built-in LLM-as-a-judge capabilities for standard metrics, or adapt the custom framework discussed in this post for specialized evaluation criteria.
- Implement multi-dimensional testing: Adapt the evaluation framework to your specific domain requirements.
- Pilot deployment: Begin with low-risk scenarios to validate performance in your environment.
- Scale systematically: Use the statistical validation approach to expand to additional use cases.
Additional resources
About the authors
 Madhu Pai, Ph.D., is a Principal Specialist Solutions Architect for Generative AI and Machine Learning at AWS. He leads strategic AI/ML initiatives that deliver scalable impact across diverse industries by identifying customer needs and building impactful solutions. Previously at AWS, Madhu served as the WW Partner Tech Lead for Manufacturing where he delivered compelling partner solutions that drove strategic outcomes for industrial manufacturing customers. He brings over 18 years of experience across multiple industries, leveraging data, AI, and ML to deliver measurable business results.
Madhu Pai, Ph.D., is a Principal Specialist Solutions Architect for Generative AI and Machine Learning at AWS. He leads strategic AI/ML initiatives that deliver scalable impact across diverse industries by identifying customer needs and building impactful solutions. Previously at AWS, Madhu served as the WW Partner Tech Lead for Manufacturing where he delivered compelling partner solutions that drove strategic outcomes for industrial manufacturing customers. He brings over 18 years of experience across multiple industries, leveraging data, AI, and ML to deliver measurable business results.
 Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
Sunita Koppar is a Senior Specialist Solutions Architect in Generative AI and Machine Learning at AWS, where she partners with customers across diverse industries to design solutions, build proof-of-concepts, and drive measurable business outcomes. Beyond her professional role, she is deeply passionate about learning and teaching Sanskrit, actively engaging with student communities to help them upskill and grow.
 Satyanarayana Adimula is a Senior Builder in the AWS GenAI Invocation Center. With over 20 years of experience in data and analytics and deep expertise in generative AI, he helps organizations achieve measurable business outcomes. He builds agentic AI systems that automate workflows, accelerate decision-making, reduce costs, increase productivity, and create new revenue opportunities. His work spans large enterprise customers across various industries, including retail, banking, financial services, insurance, healthcare, media and entertainment, and professional services.
Satyanarayana Adimula is a Senior Builder in the AWS GenAI Invocation Center. With over 20 years of experience in data and analytics and deep expertise in generative AI, he helps organizations achieve measurable business outcomes. He builds agentic AI systems that automate workflows, accelerate decision-making, reduce costs, increase productivity, and create new revenue opportunities. His work spans large enterprise customers across various industries, including retail, banking, financial services, insurance, healthcare, media and entertainment, and professional services.



